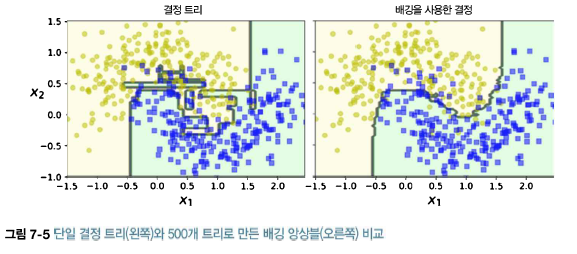
다양한 분류기를 만드는 한가지 방법은 각기 다른 훈련 알고리즘을 사용하는 것이다. 또 다른 방법은 같은 알고리즘을 사용하고 훈련 세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 것이다. 훈련 세트에서 중복을 허용하여 샘플링 하는 방식을 배깅(bagging, bootstrap aggregating의 줄임말)이라 하며, 중복을 허용하지 않고 샘플링 하는 방식을 페이스팅(pasting)이라고 한다. 모든 예측기가 훈련을 마치면 앙상블은 모든 예측기의 예측을모아서 새로운 샘플에 대한 예측을 만든다. 수집 함수는 전형적으로 분류일 때는 통계적 최빈값이고, 회귀에 대해서는 평균을 계산한다. 개별 예측기는 원본 휸련 세트로 훈련시킨 것보다 훨씬 크게 편향되어 있지만 수집 함수를 통과하면 편향과 분산..