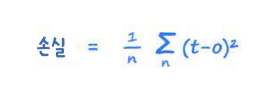GAN을 훈련할 때, 제일 이상적인 상태는 판별기와 생성기가 균형을 이룬 상태이다. 이렇게 되면 판별기는 더는 생성된 데이터와 실제 데이터를 구별하지 못한다. 이 균형이 도달했을 때 판별기의 손실이 어떻게 되는지 확인해보자. MSE 손실 평균제곱오차 손실의 정의는 간단하다. 출력 노드에서 나온 값과 원하는 목푯값 사이의 차이를 계산하면 된다. 이 오차를 제곱한다면 값은 항상 양이다. 평균제곱오차는 이 제곱한 오차들의 평균이다. 판별기의 결과가 0.5인 이유는 데이터가 생성된 것인지, 진짜인지 양쪽 다 같은 크기로 잘 판단할 수 없다는 의미이다. 출력이 0.5이고 목표가 1이라면 오차는 0.5일 것이다. 반대로 목표가 0이면 오차는 -0.5이다. 두 오차 모두 제곱하면 결과는 0.25가 된다. 따라서 균형..