이미지를 생성하는 것보다 간단한 작업으로 먼저 '1010 패턴' 형식의 값을 생성하는 GAN을 구현해보자.

import torch
import torch.nn as nn
import numpy as np
import pandas
import matplotlib.pyplot as plt
- 실제 데이터 소스
실제 데이터에 대하여 1010패턴을 반환하는 함수는 다음과 같이 만들 수 있다.
def generate_real():
real_data=torch.FloatTensor([1,0,1,0])
return real_data실제 세계의 데이터는 정확히 딱 떨어지는 값일 확률이 거의 없기 때문에, 약간의 임의성을 추가하여 이 함수를 조금 더 실제 상황과 가깝게 만들어보자.
import random
def generate_real():
real_data=torch.FloatTensor(
[random.uniform(0.8,1.0),
random.uniform(0.0,0.2),
random.uniform(0.8,1.0),
random.uniform(0.0,0.2)]
)
return real_data
- 판별기 만들기
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model=nn.Sequential(
nn.Linear(4,3),
nn.Sigmoid(),
nn.Linear(3,1),
nn.Sigmoid()
)
# 손실함수 설정
self.loss_function=nn.MSELoss()
# SGD 옵티마이저 설정
self.optimizer=torch.optim.SGD(self.parameters(),lr=0.01)
# 진행 측정을 위한 변수 초기화
self.counter=0
self.progress=[]
pass
def forward(self,inputs):
return self.model(inputs)
def train(self,inputs,targets):
outputs=self.forward(inputs)
loss=self.loss_function(outputs,targets)
# 카운터를 증가시키고 10회마다 오차 저장
self.counter+=1
if (self.counter%10 ==0):
self.progress.append(loss.item())
pass
if(self.counter % 10000==0):
print('counter =',self.counter)
pass
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
pass
def plot_progress(self):
df=pandas.DataFrame(self.progress,columns=['loss'])
df.plot(ylim=(0,1.0),figsize=(16,8),alpha=0.1,marker='.',grid=True,yticks=(0,0.25,0.5))
pass네트워크 자체는 단순핟. 입력 레이어에서는 네 개의 입력을 받는다. 계속해서 네 개의 값으로 이루어진 패턴만 입력에 쓰일 것이기 때문이다. 마지막 레이어에서는 단일 값을 출력한다. 참인 경우 1을 출력하고 거짓이면 0을 출력한다.
- 판별기 테스트하기
현재는 아직 생성기를 만들기 전이므로, 판별기가 생성기와 제대로 경쟁하는지 진짜 테스트하기는 어렵다. 여기서 해볼 수 있는 확인 절차는 판별기가 임의의 데이터에 대하여 진짜를 구별할 수 있느냐에 대한 부분이다.
이 테스트를 통해 판별기가 적어도 쓸모없는 노이즈로부터 실제 데이터를 골라낼 정도의 성능을 가졌는지 여부는 확인할 수 있다.

이제 제대로 분류하면 보상을 받는 훈련 과정으로 판별기를 훈련해보자.
D=Discriminator()
for i in range(10000):
D.train(generate_real(),torch.FloatTensor([1.0]))
D.train(generate_random(4),torch.FloatTensor([0.0]))
passD.plot_progress()
print(D.forward(generate_real()).item())
print(D.forward(generate_random(4)).item())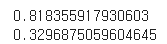
결과를 통해 판별기가 잘 작동하는 것을 알 수 있다.
지금까지 우리는 실제 데이터에서 나오는 패턴과 가짜 데이터에서 나오는 패턴을 넣었을 때 결과가 다른지 확인할 수 있게 되었다.
- 생성기 만들기

class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model=nn.Sequential(
nn.Linear(1,3),
nn.Sigmoid(),
nn.Linear(3,4),
nn.Sigmoid()
)
self.optimizer=torch.optim.SGD(self.parameters(),lr=0.01)
self.counter=0
self.progress=[]
pass
def forward(self,inputs):
return self.model(inputs)
def train(self,D,inputs,targets):
# 신경망 출력 계산
g_output=self.forward(inputs)
# 판별기로 전달
d_output=D.forward(g_output)
# 오차 계산
loss=D.loss_function(d_output,targets)
# 카운터를 증가시키고 10회마다 오차 저장
self.counter +=1
if(self.counter % 10 ==0):
self.progress.append(loss.item())
pass
# 기울기를 초기화하고 역전파 후 가중치 갱신
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
pass
def plot_progress(self):
df=pandas.DataFrame(self.progress,columns=['loss'])
df.plot(ylim=(0,1.0),figsize=(16,8),alpha=0.1,marker='.',grid=True,yticks=(0,0.25,0.5))
pass
생성자 클래스에는 self.loss가 없다. 그 이유는 이 과정이 사실 필요 없기 때문이다.
GAN 훈련 반복문에서 손실함수는 오직 판별기의 결과에만 적용이 된다는 것을 알 수 있다. 생성기는 판별기로부터 흘러온 기울기 오차를 통해 업데이트가 된다.
결과적으로, 생성기를 훈련시킬 때는 판별기가 필요하다. 깔끔한 방식 하나는 판별기를 생성기의 train() 함수에 넘겨주는 방법이다.
손실은 d_output과 정답지(원하는 목푯값) 간의 차이로 계산이 된다. 이 손실로부터 오차가 역전파되며, 이는 판별기에서 계산 그래프를 통해 생성기로 전해진다.
이 업데이트는 D.optimizer가 아닌 self.optimizer를 통해 전해진다. 이 방법으로, GAN 훈련 과정의 3단계에서 의도한 것과 같이, 생성기의 가중치만 업데이트한다.
G=Generator()
G.forward(torch.FloatTensor([0.5]))
물론 이 패턴은 1010형태는 아니다. 생성기는 아직 훈련이 되어 있지 않기 때문이다.
- GAN 훈련하기
D=Discriminator()
G=Generator()
%%time
image_list=[]
for i in range(10000):
if(i%1000==0):
image_list.append(G.forward(torch.FloatTensor([0.5])).detach().numpy())
# 1단계: 참에 대해 판별기 훈련
D.train(generate_real(),torch.FloatTensor([1.0]))
# 2단계: 거짓에 대해 판별기 훈련
# G의 기울기가 계산되지 않도록 detach() 함수를 이용
D.train(G.forward(torch.FloatTensor([0.5])).detach(),torch.FloatTensor([0.0]))
# 3단계: 생성기 훈련
G.train(D,torch.FloatTensor([0.5]),torch.FloatTensor([1.0]))
pass
2단계 에서 detach()는 생성기의 출력에 적용되어 계산 그래프에서 생성기를 떼어내는 역할을 한다.
일반적으로 backwards()를 판별기의 손실에 호출하는 행위는 기울기 오차를 계산 그래프의 전 과정에 걸쳐서 계산하라는 의미이다.
이는 판별기의 손실부터, 판별기 그 자체, 그리고 생성기까지 전해진다. 현재는 판별기를 훈련하는 중이기 때문에 생성기의 기울기를 계산해야 할 이유가 없다.
detach()는 생성기의 출력에 적용이 되며, 계산 그래프의 특정 부분에서 연산을 끝나게 한다.
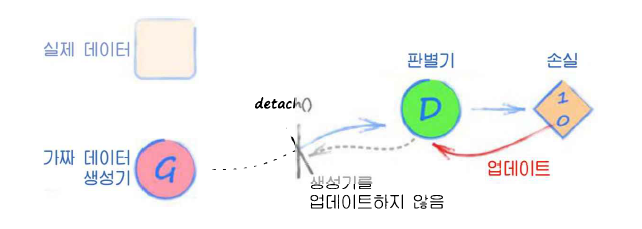
3단계는 생성기를 훈련하고 생성기의 입력값을 0.5로 설정한 후 판별기 객체에 전달하는 단계이다. 이번에는 detach()를 쓰지 않았는데 왜냐하면 오차가 판별기로부터 쭈욱 생성기까지 전해져야 하기 때문이다. 생성기의 train() 함수는 생성기의 가중치만을 업데이트할 뿐이므로, 판별기에 뭔가 특별한 작업은 필요하지 않는다.
이제 판별기의 손실을 D.plot_progress()를 통해 한번 그려보면서 훈련이 어떻게 진행되었나 살펴보자.
D.plot_progress()
이 예제에서는 손실이 0.25 근처에서 맴돌고 있다. 이 숫자는 대체 무엇을 의미하는 것일까?
판별기가 실제 데이터와 조작된 데이터를 잘 판별하지 못하는 결과를 내놓는 다면, 그 결과로 0.0이나 1.0의 확실한 결과가 아니라 애매한 0.5라는 결과를 내놓을 것이다. 우리는 현재 평균제곱오차를 이용했기 때문에 0.5를 제곱한 0.25가 손실로 나오는 것이다.
이제 생성기를 훈련할 때 볼 수 있었던 손실값을 살펴보자.
G.plot_progress()
차트를 통해, 초반에는 판별기가 가짜인지 진짜인지 잘 분류를 못 하는 현상을 확인할 수 있다. 중반에는 손실이 살짝 올라간 것을 볼 수 있고, 이는 생성기가 어느 정도 판별기를 속일 수 있을 정도로 성능이 향상했다는 것을 뜻한다. 훈련의 마지막에 도달할 때쯤 다시 한번 판별기와 생성기 간에 균형이 생긴 것을 확인할 수 있다.
이제 생성기가 만들어낸 데이터를 보고 어떤 패턴을 만들어냈는지 확인해보자.
G.forward(torch.FloatTensor([0.5]))
결과를 보면 생성기가 정말로 1010패턴을 만들어냈다는 것을 알 수 있다.

잘 훈련된 GAN은 생성된 가짜 이미지와 실제 이미지를 잘 구별하지 못하는 상태이다. 즉 출력은 0.5로서 0.0과 1.0의 중간에 해당하는 값이다. 평균제곱오차의 이상적인 값은 0.25이다.
'GAN > 이론' 카테고리의 다른 글
| 5. 손으로 쓴 숫자 훈련(2) (0) | 2021.11.03 |
|---|---|
| 4. 손으로 쓴 숫자 훈련 (1) (0) | 2021.11.03 |
| 2. GAN 개념 (0) | 2021.10.31 |
| 1. CUDA 기초 (0) | 2021.10.31 |
| ===================================================== (0) | 2021.10.31 |