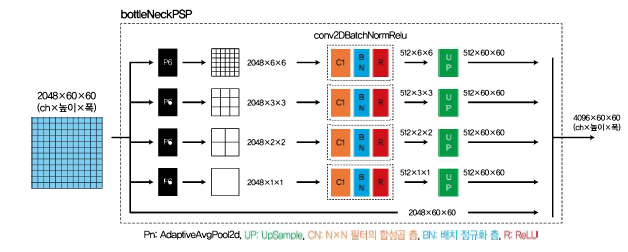
추론 파일 경로 리스트를 만든다. VOC 데이터셋 화상이 아니라 승마 화상에 대해 추론하며 어노테이션 화상을 한 장 사용한다. 어노테이션 화상을 사용하는 두 가지 이유가 있다. 첫째, 어노테이션 화상이 없으면 전처리 클래스의 함수가 제대로 작동하지 않게 된다. 실제로는 추론에 사용하지 않지만 더미 데이터로서 함수에 전달한다. 둘째, 어노테이션 화상에서 색상 팔레트 정보를 추출하지 않으면 물체 라벨에 해당하는 색상 정보가 존재하지 않게 된다. from utils.dataloader import make_datapath_list, DataTransform # 파일 경로 리스트 작성 rootpath = "./data/VOCdevkit/VOC2012/" train_img_list, train_anno_list,..