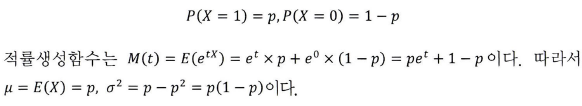베르누이 분포
보험사기 여부, 제조 공정에서의 합격/불합격 여부, 동전을 던지는 경우 앞면이 나오는 시행 등은 결과가 1 또는 0인 경우이다. 이러한 시행을 베르누이 시행이라고 한다. 베르누이 시행은 시행의 결과가 2가지뿐이며 확률변수로는 보통 1을 성공, 0을 실패로 정의한다. 이때 성공의 확률은 p로 실패의 확률은 q=1-로 표기한다. # 표본의 개수: 10 trials=1 event_prob=1/6 size=10 np.random.seed(123) result=np.random.binomial(n=trials,p=event_prob,size=size) result # array([0, 0, 0, 0, 0, 0, 1, 0, 0, 0]) # 성공 건수 np.sum(result) # 1 기댓값, 즉 평균값 p의 의미는..