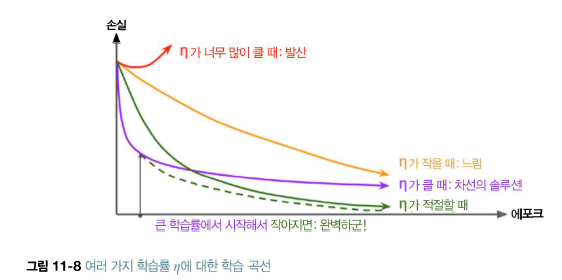
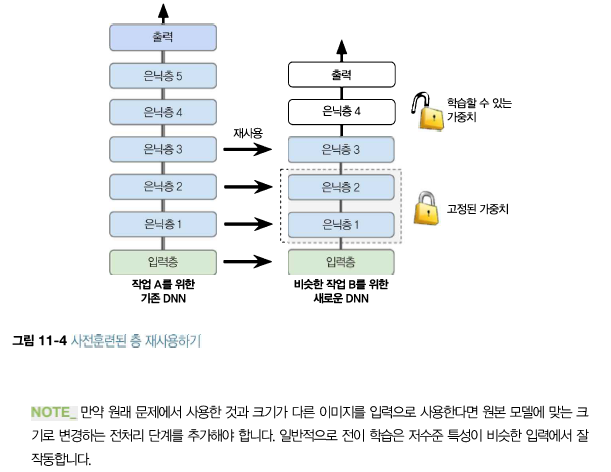
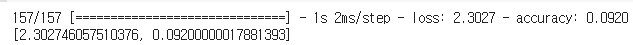CIFAR10 이미지 데이터셋에 심층 신경망을 훈련해보자. 먼저 100개의 뉴런을 가진 은닉층 20개로 심층 신경망을 만든다. He 초기화와 ELU 활성화 함수를 사용한다. from tensorflow import keras model=keras.models.Sequential() model.add(keras.layers.Flatten(input_shape=[32,32,3])) for _ in range(20): model.add(keras.layers.Dense(100, activation='elu', kernel_initializer='he_normal')) 그 다음 Nadam 옵티마이저와 조기 종료를 사용하여 CIFAR10 데이터셋에 이 네트워크를 훈련하자. 이 데이터셋은 10개의 클래스와 32x3..