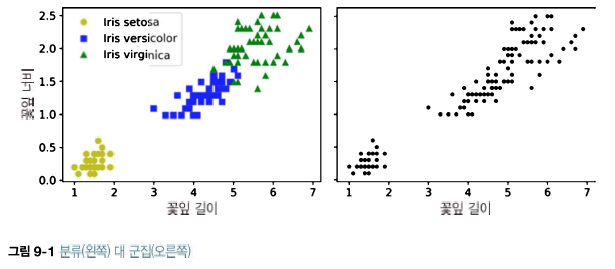
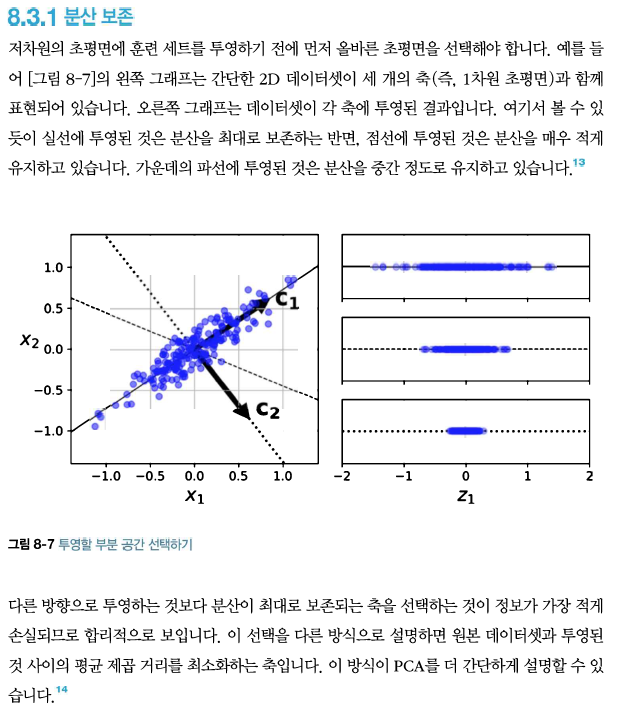
최적의 클러스터 개수 찾기 일반적으로 k를 어떻게 설정할지 쉽게 알 수 없다. 만약 올바르게 지정하지 않으면 결과는 매우 나쁠 수 있다. 더 정확한 방법은 실루엣 점수(silhouette score)이다. 이 값은 모든 샘플에 대한 실루엣 계수의 평균이다. 샘플의 실루엣 계수는 (b-a)/max(a,b)로 계산한다. 여기에서 a는 동일한 클러스터에 있는 다른 샘플까지 평균 거리이다(즉 클러스터 내부의 평균 거리). b는 가장 가까운 클러스터까지 평균 거리이다(즉 가장 가까운 클러스터의 샘플까지 평균 거리, 샘플과 가장 가까운 클러스터는 자신이 속한 클러스터는 제외하고 b가 최소인 클러스터이다). 실루엣 계수는 -1에서 1까지 바뀔 수 있다. +1에 가까우면 자신의 클러스터가 안에 잘 속해 있고 다른 클러..