
군집이란(clustering) 비슷한 샘플을 구별해 하나의 클러스터(cluster) 또는 비슷한 샘플의 그룹으로 할당하는 작업이다.
다음 그림의 오른쪽은 레이블이 없다. 따라서 더는 분류 알고리즘을 사용할 수 없다. 이럴때 군집 알고리즘이 필요하다.
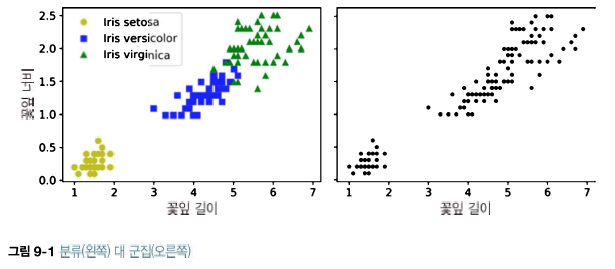
클러스터에 대한 보편적인 정의는 없다. 실제로 상황에 따라 다르다. 알고리즘이 다르면 다른 종류의 클러스터를 감지한다. 이떤 알고리즘은 센트로이드(centroid)라 부르는 특정 포인트를 중심으로 모인 샘플을 찾는다. 어떤 알고리즘은 샘플이 밀집되어 연속된 영역을 찾는다. 이런 클러스터는 어떤 모양이든 될 수 있다.
< k-평균 >
k-평균은 반복 몇 번으로 이런 종류의 데이터셋을 빠르고 효율적으로 클러스터로 묶을 수 있는 간단한 알고리즘이다.


실제 k-평균 알고리즘은 클러스터의 크기가 많이 다르면 잘 작동하지 않는다. 샘플을 클러스터에 할당할 때 센트로이드까지 거리를 고려하는 것이 전부이기 때문이다.
하드 군집(hard clustering)이라는 샘플을 하나의 클러스터에 할당하는 것보다 클러스터마다 샘플에 점수를 부여하는 것이 유용할 수 있다. 이를 소프트 군집(soft clustering)이라고 한다. 이 점수는 샘플과 센트로이드 사이의 거리가 될 수 있다. KMeans 클래스의 transform() 메서드는 샘플과 각 센트로이드 사이의 거리를 반환한다.






k-평균 속도 개선과 미니배치 k-평균
불필요한 계산을 많이 피함으로써 알고리즘의 속도를 상당히 높일 수 있다. 이 알고리즘은 KMeans 클래스에서 기본으로 사용한다.
k-평균 알고리즘의 또 다른 중요한 변종이 시작되었는데 전체 데이터셋을 사용해 반복하지 않고 이 알고리즘은 반복마다 미니배치를 사용해 센트로이드를 조금씩 이동한다. 이는 3,4배 속도를 증가시켰다.


'Machine Learning > Advanced (hands on machine learning)' 카테고리의 다른 글
| 30. 비지도학습 - DBSCAN (0) | 2021.05.30 |
|---|---|
| 29. 비지도학습 - 군집(k-평균(2)) (0) | 2021.05.26 |
| 26. 차원 축소 - 커널 PCA (0) | 2021.05.26 |
| 25. 차원 축소 - PCA (0) | 2021.05.26 |
| 24. 차원 축소 - 차원의 저주 (0) | 2021.05.26 |