MNIST 데이터셋을 로드하고 훈련 세트와 테스트 세트로 분할한다. 이 데이터셋에 랜덤 포레스트 분류기를 훈련시키고 얼마나 오래 걸리는지 시간을 잰 다음, 테스트 세트로 만들어진 모델을 평가한다. 그런 다음 PCA를 사용해 설명된 분산이 95%가 되도록 차원을 축소한다. 이 축소된 데이터셋에 새로운 랜덤 포레스트 분류기를 훈련시키고 얼마나 오래 걸리즌지 확인한다. 훈련 속도가 더 빨라졌나? 이제 테스트 세트에서 이 분류기를 평가해보자. 이전 분류기와 비교해서 어떤가?
from sklearn.datasets import fetch_openml
mnist=fetch_openml('mnist_784',version=1)
X_train=mnist['data'][:60000]
y_train=mnist['target'][:60000]
X_test=mnist['data'][60000:]
y_test=mnist['target'][60000:]from sklearn.ensemble import RandomForestClassifier
import time
rnd_clf=RandomForestClassifier(n_estimators=100,random_state=42)
t0=time.time()
rnd_clf.fit(X_train,y_train)
t1=time.time()
print(t1-t0)
from sklearn.metrics import accuracy_score
y_pred=rnd_clf.predict(X_test)
accuracy_score(y_test,y_pred)
PCA를 사용해 설명된 분산이 95%가 되도록 차원을 축소한다.
from sklearn.decomposition import PCA
pca=PCA(n_components=0.95)
X_train_reduced=pca.fit_transform(X_train)
rnd_clf2=RandomForestClassifier(n_estimators=100,random_state=42)
t0=time.time()
rnd_clf2.fit(X_train_reduced,y_train)
t1=time.time()
print(t1-t0)
훈련 시간이 늘어났다. 이렇든 차원 축소는 언제나 훈련 시간을 줄여주지 못한다. 데이터셋, 모델, 훈련, 알고리즘에 따라 달라진다.
테스트 세트에서 이 분류기를 평가해보자.
X_test_reduced=pca.transform(X_test)
y_pred=rnd_clf2.predict(X_test_reduced)
accuracy_score(y_test,y_pred)
차원 축소를 했을 때 유용한 정보를 일부 잃었기 때문에 성능이 조금 감소되는 것이 일반적이다. 그렇지만 이 경우에는 성능 감소가 좀 심각한것 같다. PCA가 별로 도움이 되지 않았다.
소프트맥스 회귀를 사용하면 도움이 되는지 확인해보자.
from sklearn.linear_model import LogisticRegression
log_clf=LogisticRegression(multi_class='multinomial',solver='lbfgs',random_state=42)
t0=time.time()
log_clf.fit(X_train,y_train)
t1=time.time()
t1-t0
y_pred=log_clf.predict(X_test)
accuracy_score(y_test,y_pred)
log_clf2 = LogisticRegression(multi_class="multinomial", solver="lbfgs", random_state=42)
t0 = time.time()
log_clf2.fit(X_train_reduced, y_train)
t1 = time.time()
t1-t0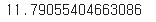
y_pred=log_clf2.predict(X_test_reduced)
accuracy_score(y_test,y_pred)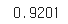
차원 축소가 속도를 2배 이상 빠르게 만들었다. 성능은 조금 감소되었지만 애플리케이션에 따라서 2배 이상의 속도 향상에 대한 댓가로 적절한것 같다.
결론: PCA는 속도를 아주 빠르게 만들어 주지만 항상 그런것은 아니다