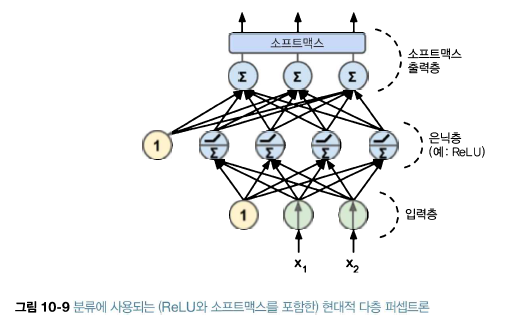
5. 케라스로 다층 퍼셉트론 구현(2) - 시퀀셜 API 회귀, 함수형 API
캘리포니아 주택 가격 데이터셋으로 바꾸어 회귀 신경망으로 이를 해결해보자. from sklearn.datasets import fetch_california_housing from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler housing=fetch_california_housing() X_train_full,X_test,y_train_full,y_test=train_test_split(housing.data,housing.target) X_train,X_valid,y_train,y_valid=train_test_split(X_train_full,y_train_full) sca..