전통적인 올리베티 얼굴 데이터셋은 64x64 픽셀 크기의 흑백 얼굴 이미지 400개를 담고 있다. 각 이미지는 4096크기의 ID 벡터로 펼쳐져 있다. 사람 40명의 사진을 10장씩 찍은 것이다. 어떤 사람의 사진인지 예측하는 모델을 훈련하는 것이 일반적이다. sklearn.datasets.fetch_olivetti_faces() 함수를 사용해 데이터셋을 불러오고 훈련 세트, 검증 세트, 테스트 세트로 나눈다.(이 데이터셋은 이미 0에서 1사이로 스케일이 조정되어 있다.). 이 데이터셋은 매우 작으니 계층적 샘플링을 사용해 각 세트에 동일한 사람의 얼굴이 고루 섞이도록 하는 것이 좋다. 그다음 k-평균을 사용해 이미지를 군집해보자. 적절한 클러스터 개수를 찾아보고 클러스터를 시각화해보자.
from sklearn.datasets import fetch_olivetti_faces
olivetti=fetch_olivetti_faces()olivetti.keys()
print(olivetti.DESCR)
olivetti.target
데이터 셋을 훈련 세트, 검증 세트, 테스트 세트로 나누자. 이 데이터 셋은 매우 작으니 계층적 샘플링을 사용해 각 세트에 동일한 사람의 얼굴이 고루 섞이도록 하는 것이 좋다.
from sklearn.model_selection import StratifiedShuffleSplit
strat_split=StratifiedShuffleSplit(n_splits=1,test_size=40,random_state=42)
train_valid_idx,test_idx=next(strat_split.split(olivetti.data,olivetti.target))
X_train_valid=olivetti.data[train_valid_idx]
y_train_valid=olivetti.target[train_valid_idx]
X_test=olivetti.data[test_idx]
y_test=olivetti.target[test_idx]
strat_split=StratifiedShuffleSplit(n_splits=1,test_size=80,random_state=43)
train_idx,valid_idx=next(strat_split.split(X_train_valid,y_train_valid))
X_train=X_train_valid[train_idx]
y_train=y_train_valid[train_idx]
X_valid=X_train_valid[valid_idx]
y_valid=y_train_valid[valid_idx]
print(X_train.shape,y_train.shape)
print(X_valid.shape,y_valid.shape)
print(X_test.shape,y_test.shape)
속도를 높이기 위해 PCA로 데이터의 차원을 줄인다.
from sklearn.decomposition import PCA
pca=PCA(0.99)
X_train_pca=pca.fit_transform(X_train)
X_valid_pca=pca.transform(X_valid)
X_test_pca=pca.transform(X_test)
pca.n_components_
k-평균을 사용해 이미지를 군집해보자.
from sklearn.cluster import KMeans
k_range = range(5, 150, 5)
kmeans_per_k = []
for k in k_range:
print("k={}".format(k))
kmeans = KMeans(n_clusters=k, random_state=42).fit(X_train_pca)
kmeans_per_k.append(kmeans)
from sklearn.metrics import silhouette_score
silhouette_scores=[silhouette_score(X_train_pca,model.labels_)
for model in kmeans_per_k]
best_index=np.argmax(silhouette_scores)
best_k=k_range[best_index]
best_score=silhouette_scores[best_index]
import matplotlib.pyplot as plt
plt.figure(figsize=(8,3))
plt.plot(k_range,silhouette_scores,'bo-')
plt.xlabel('k')
plt.ylabel('Silhouette score')
plt.plot(best_k,best_score,'rs')
plt.show()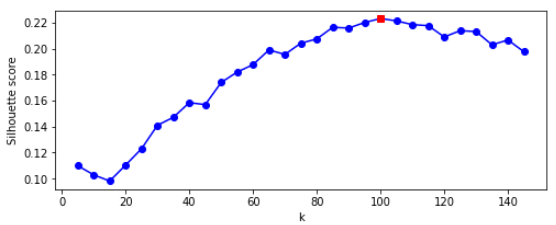
best_k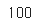
최적의 클러스터 개수는 120개로 매우 크다. 사진 속의 인물이 40명이기 때문에 아마 40정도로 예상했을 것이지만 같은 사람이 사진마다 다르게 보일 수 있다.
inertias=[model.inertia_ for model in kmeans_per_k]
best_inertia=inertias[best_index]
plt.figure(figsize=(8,3.5))
plt.plot(k_range,inertias,'bo-')
plt.xlabel('k')
plt.ylabel('Inertia')
plt.plot(best_k,best_inertia,'rs')
plt.show()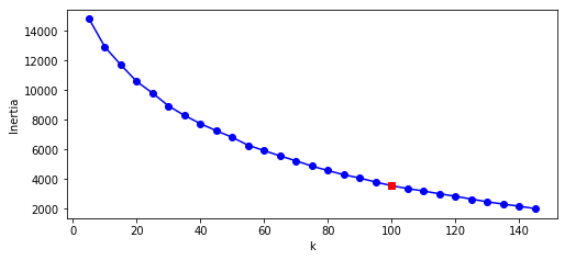
이너셔 그래프에서는 엘보우 지점이 없기 때문에 최적의 클러스터 개수가 명확하지 않다. 그냥 k=100을 사용하겠다.
best_model=kmeans_per_k[best_index]
def plot_faces(faces,labels,n_cols=5):
faces=faces.reshape(-1,64,64)
n_rows=(len(faces)-1) // n_cols+1
plt.figure(figsize=(n_cols,n_rows * 1.1))
for index,(face,label) in enumerate(zip(faces,labels)):
plt.subplot(n_rows,n_cols,index + 1)
plt.imshow(face,cmap='gray')
plt.axis('off')
plt.title(label)
plt.show()
for cluster_id in np.unique(best_model.labels_):
print('cluster',cluster_id)
in_cluster=best_model.labels_ == cluster_id
faces=X_train[in_cluster]
labels=y_train[in_cluster]
plot_faces(faces,labels)
'모델 실습' 카테고리의 다른 글
| tf.keras를 사용한 Neural Style Transfer (0) | 2021.06.16 |
|---|---|
| 5. 심층 신경망 실습 (0) | 2021.06.07 |
| 4. 다층 퍼셉트론 실습 (학습률을 바꿔가면서 학습하기) (0) | 2021.06.03 |
| 2. 앙상블 학습과 랜덤 포레스트 - 실습 (0) | 2021.05.22 |
| 1. 서포트 벡터 머신(SVM) 실습 (0) | 2021.05.20 |