MNIST 데이터셋에 SVM 분류기를 훈련시켜보자. SVM 분류기는 이진 분류기라서 OvR전략을 사용해 10개의 숫자를 분류해야 한다. 처리 속도를 높이기 위해 작은 검증 세트로 하이퍼파라미터를 조정하는 것이 좋다.
먼저 데이터셋을 로드하고 훈련 세트와 테스트 세트로 나눈다. train_test_split() 함수를 사용할 수 있지만 보통 처음 60,000개의 샘플을 훈련 세트로 사용하고 나머지는 10,00개의 테스트 세트로 사용한다.
from sklearn.datasets import fetch_openml
import numpy as np
mnist=fetch_openml('mnist_784',version=1,cache=True)
X=mnist['data']
y=mnist['target'].astype(np.uint8)
X_train=X[:60000]
y_train=y[:60000]
X_test=X[60000:]
y_test=y[60000:]많은 훈련 알고리즘은 훈련 샘플의 순서에 민감하므로 먼저 이를 섞는 것이 좋은 습관이다. 하지만 이 데이터셋은 이미 섞여있으므로 이렇게 할 필요가 없다.
선형 SVM 분류기부터 시작해보자. 이 모델은 자동으로 OvA(또는 OvR) 전략을 사용하므로 특별히 처리해 줄 것이 없다.
from sklearn.svm import LinearSVC
lin_clf=LinearSVC(random_state=42)
lin_clf.fit(X_train,y_train)
훈련 세트에 대한 예측을 만들어 정확도를 측정해 보자.
from sklearn.metrics import accuracy_score
y_pred=lin_clf.predict(X_train)
accuracy_score(y_train,y_pred)
MNIST에서 이 확률은 나쁜 성능이다. 선형 모델이 MNIST 문제에 너무 단순하기 때문이지만 먼저 데이터의 스케일을 조정할 필요가 있다.
scaler=StandardScaler()
X_train_scaled= scaler.fit_transform(X_train.astype(np.float32))
X_test_scaled=scaler.fit_transform(X_test.astype(np.float32))lin_clf=LinearSVC(random_state=42)
lin_clf.fit(X_train_scaled,y_train)
y_pred=lin_clf.predict(X_train_scaled)
accuracy_score(y_train,y_pred)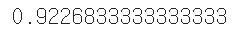
훨씬 나아졌지만 여전히 MNIST에서 좋은 성능이 아니다. SVM을 사용한다면 커널 함수를 사용해야 한다. RBF커널(기본값)로 SVC를 적용해 보겠다.
svm_clf=SVC(gamma='scale')
svm_clf.fit(X_train_scaled[:10000],y_train[:10000])
y_pred=svm_clf.predict(X_train_scaled)
accuracy_score(y_train,y_pred)
6배나 적은 데이터에서 모델을 훈련시켰지만 더 좋은 성능을 얻었다. 교차 검증을 사용한 랜덤서치로 하이퍼파라미터 튜닝을 해보겠다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import reciprocal,uniform
param_distributions={'gamma': reciprocal(0.001,0.1), 'C': uniform(1,10)}
rnd_search_cv=RandomizedSearchCV(svm_clf,param_distributions,n_iter=10,verbose=2,cv=3)
rnd_search_cv.fit(X_train_scaled[:1000],y_train[:1000])rnd_search_cv.best_estimator_
rnd_search_cv.best_score_
이 점수는 낮지만 1000개의 샘플만 사용한 것을 기억해야 한다. 전체 데이터셋으로 최선의 모델을 재훈련시켜보자.
rnd_search_cv.best_estimator_.fit(X_train_scaled,y_train)
y_pred=rnd_search_cv.best_estimator_.predict(X_train_scaled)
accuracy_score(y_train,y_pred)
y_pred=rnd_search_cv.best_estimator_.predict(X_test_scaled)
accuracy_score(y_test,y_pred)
아주 나쁘지 않지만 확실히 모델이 다소 과대적합되었습니다. 하이퍼파라미터를 조금 더 수정할 수 있지만(가령, C와/나 gamma를 감소시킵니다) 그렇게 하면 테스트 세트에 과대적합될 위험이 있습니다. 다른 사람들은 하이퍼파라미터 C=5와 gamma=0.005에서 더 나은 성능(98% 이상의 정확도)을 얻었습니다. 훈련 세트를 더 많이 사용해서 더 오래 랜덤 서치를 수행하면 이런 값을 얻을 수 있을지 모릅니다.
'모델 실습' 카테고리의 다른 글
| tf.keras를 사용한 Neural Style Transfer (0) | 2021.06.16 |
|---|---|
| 5. 심층 신경망 실습 (0) | 2021.06.07 |
| 4. 다층 퍼셉트론 실습 (학습률을 바꿔가면서 학습하기) (0) | 2021.06.03 |
| 3. 비지도학습 - 실습 (0) | 2021.05.30 |
| 2. 앙상블 학습과 랜덤 포레스트 - 실습 (0) | 2021.05.22 |