이번 포스팅은 딥러닝을 사용하여 원하는 이미지를 다른 스타일의 이미지로 구성하는 법을 공부하고 정리했다. TensorFlow공식 홈페이지에 있는 문서와 코드를 보고 공부했다.
이 기법은 Neural Style Transfer로 알려져있으며 Leon A.Gatys의 논문 A Neural Algorithm of Artistic Style에 잘 기술되어 있다. Neural style transfer은 콘텐츠 (content) 이미지와 (유명한 작가의 삽화와 같은) 스타일 참조 (style reference) 이미지를 이용하여, 콘텐츠 이미지의 콘텐츠는 유지하되 스타일 참조 이미지의 화풍으로 채색한 것 같은 새로운 이미지를 생성하는 최적화 기술이다.
< 모듈 구성 및 임포트 >
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing import image
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib.pyplot as mpl
mpl.rcParams['figure.figsize'] = (12,12) # 차트의 크기 설정
mpl.rcParams['axes.grid'] = False # 차트 내 격자선(grid) 표시 여부
import numpy as np
import PIL.Image
import time
import functools
텐서를 이미지로 변환하는 함수를 작성한다. 이 함수를 통해 이미지를 출력할 수 있다.
PIL.Image.fromarray 메서드는 numpy 배열을 PIL 이미지로 변환한다.
def tensor_to_image(tensor):
tensor = tensor * 255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0]==1 # 텐서의 첫번째 차원이 1이 아니면 프로그램 종료
tensor=tensor[0] #4차원(1,424,512,3) -> 3차원(424,512,3)
return PIL.Image.fromarray(tensor)
다음은 content_image와 style_image를 다운 받는다. content_image는 온라인에서 다운받은 파일이고 style_image는 내가 직접 인터넷에서 복사하여 작업중인 폴더에 저장해놓았고 그 사진을 불러온것이다.
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
# https://commons.wikimedia.org/wiki/File:Vassily_Kandinsky,_1913_-_Composition_7.jpg
style_image=image.load_img('/content/monk.jpg')
style_image=image.img_to_array(style_image)
style_image=style_image/255
plt.imshow(style_image)
아래 코드는 온라인에서 다운받은 이미지를 불러오는 코드이다. 그냥 직접 사진을 저장해오는 방식이 더 편한것 같다. 그렇지만 이미지 크기를 조정하는 방법은 눈여겨 볼만 한것 같다.
def load_img(path_to_img): # 이미지를 불러오는 함수를 정의하고, 최대 이미지 크기를 512개의 픽셀로 제한한다.
max_dim=512
img=tf.io.read_file(path_to_img)
img=tf.image.decode_image(img,channels=3) #int 형 [0,255]
img=tf.image.convert_image_dtype(img,tf.float32) #float형 [0,1]
shape=tf.cast(tf.shape(img)[:-1],tf.float32)
long_dim=max(shape)
scale=max_dim/long_dim
new_shape=tf.cast(shape*scale,tf.int32)
img=tf.image.resize(img,new_shape)
img=img[tf.newaxis,:]
return img
def imshow(image,title=None):
if len(image.shape) > 3:
image=tf.squeeze(image,axis=0) # (1,422,512,3) -> (422,512,3)
plt.imshow(image)
if title:
plt.title(title)여기서 중요한점이 있는데 plt.imshow로 이미지를 출력할때는 3차원의 입력이 들어와야 한다. 그러나 텐서로 사용할 때는 앞에 차원을 추가해 4차원의 입력이 들어와야 한다.
content_image=load_img(content_path)
style_image=style_image[np.newaxis,:]
plt.subplot(1,2,1)
imshow(content_image,'Content Image')
plt.subplot(1,2,2)
imshow(style_image,'Style Image')

< TF-Hub를 통한 빠른 스타일 전이 >
텐서플로 허브 모듈은 어떤 결과물을 생성하는지 시험해보자.
import tensorflow_hub as hub
hub_module = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/1')
stylized_image = hub_module(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
< 콘텐츠와 스타일 표현 정의하기 >
이미지의 콘텐츠와 스타일 표현을 얻기 위해, 모델의 몇 가지 중간층들을 살펴보자. 모델의 입력층부터 시작해서, 처음 몇 개의 층은 선분이나 질감과 같은 이미지 내의 저차원적 특성에 반응한다. 반면, 네트워크가 깊어지면 최종 몇 개의 층은 바퀴나 눈과 같은 고차원적 특성들을 나타낸다. 이번 경우, 사전학습된 이 중간층들은 이미지에서 콘텐츠와 스타일 표현을 정의하는데 필요하다. 입력 이미지가 주어졌을때, 스타일 전이 알고리즘은 이 중간층들에서 콘텐츠와 스타일에 해당하는 타깃 표현들을 일치시키려고 시도할 것이다.
VGG19 모델을 불러오고, 작동 여부를 확인하기 위해 이미지에 적용시켜보자.
x=tf.keras.applications.vgg19.preprocess_input(content_image*255) #이미지가 float형 이였으므로
x=tf.image.resize(x,(224,224))
vgg=tf.keras.applications.VGG19(include_top=True,weights='imagenet')
prediction_probabilities=vgg(x)
prediction_probabilities.shape
predicted_top_5=tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name,prob) for (number,class_name,prob) in predicted_top_5]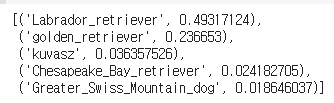
이제 분류층을 제외한 VGG19 모델을 불러오고, 각 층의 이름을 출력해보자.
vgg=tf.keras.applications.VGG19(include_top=False,weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
이미지의 스타일과 콘텐츠를 나타내기 위한 모델의 중간층들을 선택한다.
content_layers=['block5_conv2']
style_layers=['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers=len(content_layers)
num_style_layers=len(style_layers)
그렇다면 사전훈련된 이미지 분류 네트워크 속에 있는 중간 출력으로 어떻게 스타일과 콘텐츠 표현을 정의할 수 있을까? 고수준에서 보면 (네트워크의 훈련 목적인) 이미지 분류를 수행하기 위해서는 네트워크가 반드시 이미지를 이해해야 한다. 이는 미가공 이미지를 입력으로 받아 픽셀값들을 이미지 내에 존재하는 특성들에 대한 복합적인 이해로 변환할 수 있는 내부 표현을 만드는 작업이 포함된다.
또한 부분적으로 왜 합성곱 신경망의 일반화가 쉽게 가능한지를 나타낸다. 즉, 합성곱 신경망은 배경 잡음과 기타잡음에 상관없이(고양이와 강아지와 같이) 클래스 안에 있는 불변성과 특징을 포착할 수 있다. 따라서 미가공 이미지의 입력과 분류 레이블의 출력 중간 어딘가에서 모델은 복합 특성 추출기의 역할을 수행한다. 그러므로, 모델의 중간층에 접근함으로써 입력 이미지의 콘텐츠와 스타일을 추출할 수 있다.
< 모델 만들기 >
아래의 함수는 중간층들의 결과물을 배열 형태로 출력하는 VGG19 모델을 반환한다.
def vgg_layers(layer_names):
""" 중간층의 출력값을 배열로 반환하는 vgg 모델을 만듭니다."""
# 이미지넷 데이터셋에 사전학습된 VGG 모델을 불러옵니다
vgg=tf.keras.applications.VGG19(include_top=False,weights='imagenet')
vgg.trainable=False
outputs=[vgg.get_layer(name).output for name in layer_names]
model=tf.keras.Model([vgg.input],outputs)
return model
위 함수를 이용해 모델을 만들어 보자.
style_extractor=vgg_layers(style_layers)
style_outputs = style_extractor(style_image * 255) # 만들어진 model
# 각 층의 출력에 대한 통계량
for name, output in zip(style_layers,style_outputs):
print(name)
print(' 크기:', output.numpy().shape)
print(' 최솟값:',output.numpy().min())
print(' 최대값', output.numpy().max())
print(' 평균:', output.numpy().mean())
print()
< 스타일 계산하기 >
이미지의 콘텐츠는 중간층들의 특성 맵의 값들로 표현된다. 이미지의 스타일은 각 특성 맵의 평균과 피쳐맵들 사이의 상관관계로 설명할 수 있다. 이런 정보를 담고 있는 그람 행렬은 각 위치에서 특성 벡터 끼리의 외적을 구한 후, 평균 값을 냄으로써 구할 수 있다. 주어진 층에 대한 그람 행렬은 다음과 같이 계산할 수 있다.
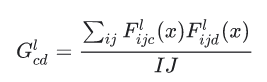
이 식은 tf.linalg.einsum 함수를 통해 쉽게 계산할 수 있다.
def gram_matrix(input_tensor):
result=tf.linalg.einsum('bijc,bijd -> bcd',input_tensor,input_tensor)
input_shape=tf.shape(input_tensor)
num_locations=tf.cast(input_shape[1] * input_shape[2], tf.float32)
return result/(num_locations)
< 스타일과 콘텐츠 추출하기 >
스타일과 콘텐츠 텐서를 반환하는 모델은 만들어보자.
class StyleContentModel(tf.keras.models.Model):
def __init__(self,style_layers,content_layers):
super(StyleContentModel,self). __init__()
self.vgg=vgg_layers(style_layers + content_layers)
self.style_layers=style_layers
self.content_layers=content_layers
self.num_style_layers=len(style_layers)
self.vgg.trainable=False
def call(self,inputs):
'[0,1] 사이의 실수 값을 입력으로 받는다'
inputs=inputs * 255.0
preprocessed_input=tf.keras.applications.vgg19.preprocess_input(inputs)
outputs=self.vgg(preprocessed_input)
style_outputs,content_outputs=(outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs=[gram_matrix(style_output) for style_output in style_outputs]
content_dict={content_name:value
for content_name,value
in zip(self.content_layers,content_outputs)}
style_dict={style_name:value
for style_name,value
in zip(self.style_layers,style_outputs)}
return {'content' : content_dict,'style': style_dict}
이미지가 입력으로 주어졌을때, 이 모델은 style_layers의 스타일과 content_layers의 콘텐츠에 대한 그람 행렬을 출력한다.
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('스타일:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" 크기: ", output.numpy().shape)
print(" 최솟값: ", output.numpy().min())
print(" 최댓값: ", output.numpy().max())
print(" 평균: ", output.numpy().mean())
print()
print("콘텐츠:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" 크기: ", output.numpy().shape)
print(" 최솟값: ", output.numpy().min())
print(" 최댓값: ", output.numpy().max())
print(" 평균: ", output.numpy().mean())
< 경사 하강법 실행 >
이제 스타일과 콘텐츠 추출기를 사용해 스타일 전이 알고리즘을 구현할 차례이다. 타깃에 대한 입력 이미지의 평균 제곱 오차를 계산한 후, 오차값들의 가중합을 구한다.
스타일과 콘텐츠의 타깃값을 지정한다.
style_targets=extractor(style_image)['style']
content_targets=extractor(content_image)['content']
최적화시킬 이미지를 담을 tf.Variable을 정의하고 콘텐츠 이미지로 초기화한다. 이때 tf.Variable는 콘텐츠 이미지와 크기가 같아야 한다.
image=tf.Variable(content_image)픽셀 값이 실수이므로 0과1사이로 클리핑하는 함수를 정의한다.
def clip_0_1(image):
return tf.clip_by_value(image,clip_value_min=0.0,clip_value_max=1.0)옵티마이저를 생성한다. 참조 연구에서는 LBFGS를 추천하지만 Adam도 충분히 적합하다.
opt=tf.optimizers.Adam(learning_rate=0.02,beta_1=0.99,epsilon=1e-1)최적화를 진행하기 위해, 전체 오차를 콘텐츠와 스타일 오차의 가중합으로 정의한다.
style_weight=1e-2
content_weight=1e4def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs=extractor(image)
loss=style_content_loss(outputs)
grad=tape.gradient(loss,image)
opt.apply_gradients([(grad,image)])
image.assign(clip_0_1(image))
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)
잘 작동하는 것을 확인했으니, 더 오랫동안 최적화를 진행해보자.
import time
start=time.time()
epochs=10
steps_per_epoch=100
step=0
for n in range(epochs):
for m in range(steps_per_epoch):
step+=1
train_step(image)
print(".",end='')
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print('훈련스텝 : {}'.format(step))
end=time.time()
print('전체 소요 시간 : {}'.format(end-start))
'모델 실습' 카테고리의 다른 글
| 5. 심층 신경망 실습 (0) | 2021.06.07 |
|---|---|
| 4. 다층 퍼셉트론 실습 (학습률을 바꿔가면서 학습하기) (0) | 2021.06.03 |
| 3. 비지도학습 - 실습 (0) | 2021.05.30 |
| 2. 앙상블 학습과 랜덤 포레스트 - 실습 (0) | 2021.05.22 |
| 1. 서포트 벡터 머신(SVM) 실습 (0) | 2021.05.20 |