CIFAR10 이미지 데이터셋에 심층 신경망을 훈련해보자.
먼저 100개의 뉴런을 가진 은닉층 20개로 심층 신경망을 만든다. He 초기화와 ELU 활성화 함수를 사용한다.
from tensorflow import keras
model=keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[32,32,3]))
for _ in range(20):
model.add(keras.layers.Dense(100,
activation='elu',
kernel_initializer='he_normal'))
그 다음 Nadam 옵티마이저와 조기 종료를 사용하여 CIFAR10 데이터셋에 이 네트워크를 훈련하자. 이 데이터셋은 10개의 클래스와 32x32 크기의 컬러 이미지 60,000개로 구성된다. 따라서 10개의 뉴런과 소프트맥스 활성화함수를 사용하는 출력층이 필요하다.
from keras.datasets import cifar10
model.add(keras.layers.Dense(10,activation='softmax'))
optimizer=keras.optimizers.Nadam(lr=5e-5)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])(X_train_full,y_train_full),(X_test,y_test)=keras.datasets.cifar10.load_data()
X_train=X_train_full[5000:]
y_train=y_train_full[5000:]
X_valid=X_train_full[:5000]
y_valid=y_train_full[:5000]
이제 콜백을 만들고 모델을 훈련한다.
import os
early_stopping_cb = keras.callbacks.EarlyStopping(patience=20)
model_checkpoint_cb = keras.callbacks.ModelCheckpoint("my_cifar10_model.h5", save_best_only=True)
run_index = 1 # 모델을 훈련할 때마다 증가시킴
run_logdir = os.path.join(os.curdir, "my_cifar10_logs", "run_{:03d}".format(run_index))
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
callbacks = [early_stopping_cb, model_checkpoint_cb, tensorboard_cb]model.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=callbacks)model=keras.models.load_model('my_cifar10_model.h5')
model.evaluate(X_valid,y_valid)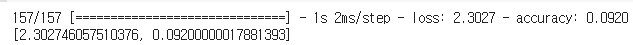
이제 배치 정규화를 추가하고 학습 곡선을 비교해보자.
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[32, 32, 3]))
model.add(keras.layers.BatchNormalization())
for _ in range(20):
model.add(keras.layers.Dense(100, kernel_initializer="he_normal"))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("elu"))
model.add(keras.layers.Dense(10, activation="softmax"))
optimizer = keras.optimizers.Nadam(lr=5e-4)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=optimizer,
metrics=["accuracy"])
early_stopping_cb = keras.callbacks.EarlyStopping(patience=20)
model_checkpoint_cb = keras.callbacks.ModelCheckpoint("my_cifar10_bn_model.h5", save_best_only=True)
run_index = 1 # 모델을 훈련할 때마다 증가시킴
run_logdir = os.path.join(os.curdir, "my_cifar10_logs", "run_bn_{:03d}".format(run_index))
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
callbacks = [early_stopping_cb, model_checkpoint_cb, tensorboard_cb]
model.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=callbacks)
model = keras.models.load_model("my_cifar10_bn_model.h5")
model.evaluate(X_valid, y_valid)
이전 모델보다 빠르게 수렴하고 더 좋은 모델을 만들었다. 또한 BN 층에서 추가된 계산 때문에 각 에포크가 걸린 시간은 증가했다. 그러나 모델은 훨씬 빠르게 수렴했다.
배치 정규화를 SELU로 바꾸어보자. 네트워크가 자기 정규화하기 위해 필요한 변경 사항을 적용해보자. (입력 특성 표준화, 르쿤 정규분포 초기화, 완전 연결 층만 순차적으로 쌓은 심층 신경망 등)
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[32, 32, 3]))
for _ in range(20):
model.add(keras.layers.Dense(100,
kernel_initializer="lecun_normal",
activation="selu"))
model.add(keras.layers.Dense(10, activation="softmax"))
optimizer = keras.optimizers.Nadam(lr=7e-4)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=optimizer,
metrics=["accuracy"])
early_stopping_cb = keras.callbacks.EarlyStopping(patience=20)
model_checkpoint_cb = keras.callbacks.ModelCheckpoint("my_cifar10_selu_model.h5", save_best_only=True)
run_index = 1 # 모델을 훈련할 때마다 증가시킴
run_logdir = os.path.join(os.curdir, "my_cifar10_logs", "run_selu_{:03d}".format(run_index))
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
callbacks = [early_stopping_cb, model_checkpoint_cb, tensorboard_cb]
X_means = X_train.mean(axis=0)
X_stds = X_train.std(axis=0)
X_train_scaled = (X_train - X_means) / X_stds
X_valid_scaled = (X_valid - X_means) / X_stds
X_test_scaled = (X_test - X_means) / X_stds
model.fit(X_train_scaled, y_train, epochs=100,
validation_data=(X_valid_scaled, y_valid),
callbacks=callbacks)
model = keras.models.load_model("my_cifar10_selu_model.h5")
model.evaluate(X_valid_scaled, y_valid)
배치 정규화를 사용한 모델만큼 좋지도 않고 원래 모델보다 좋지도 않다. 하지만 BN 모델만큼 빨리 수렴했다. 각 에포크가 걸린 시간도 매우 짧다. 따라서 이 모델이 지금까지 가장 빠른 모델이다.
알파 드롭아웃으로 모델에 규제를 적용해보자. 그다음 모델을 다시 훈련하지 않고 MC 드롭아웃으로 더 높은 정확도를 얻을 수 있는지 확인해보자.
keras.backend.clear_session()
model=keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[32,32,3]))
for _ in range(20):
model.add(keras.layers.Dense(100,kernel_initializer='lecun_normal',
activation='selu'))
model.add(keras.layers.AlphaDropout(rate=0.1))
model.add(keras.layers.Dense(10,activation='softmax'))
optimizer=keras.optimizers.Nadam(lr=5e-4)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
early_stopping_cb=keras.callbacks.EarlyStopping(patience=20)
model_checkpoint_cb=keras.callbacks.ModelCheckpoint('my_cifar10_alpha_dropout_model.h5',save_best_only=True)
run_index=1
run_logdir=os.path.join(os.curdir,'my_cifar10_logs','run_alpha_dropout_{:03d}'.format(run_index))
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
callbacks=[early_stopping_cb,model_checkpoint_cb,tensorboard_cb]
X_means=X_train.mean(axis=0)
X_stds=X_train.std(axis=0)
X_train_scaled=(X_train-X_means)/X_stds
X_valid_scaled=(X_valid-X_means)/X_stds
X_test_scaled=(X_test-X_means)/X_stds
model.fit(X_train_scaled,y_train,epochs=100,
validation_data=(X_valid_scaled,y_valid),
callbacks=callbacks)
model=keras.models.load_model('my_cifar10_alpha_dropout_model.h5')
model.evaluate(X_valid_scaled,y_valid)
드롭아웃이 없을 때보다 조금 더 좋다.
'모델 실습' 카테고리의 다른 글
| tf.keras를 사용한 Neural Style Transfer (0) | 2021.06.16 |
|---|---|
| 4. 다층 퍼셉트론 실습 (학습률을 바꿔가면서 학습하기) (0) | 2021.06.03 |
| 3. 비지도학습 - 실습 (0) | 2021.05.30 |
| 2. 앙상블 학습과 랜덤 포레스트 - 실습 (0) | 2021.05.22 |
| 1. 서포트 벡터 머신(SVM) 실습 (0) | 2021.05.20 |