심층 다층 퍼셉트론을 MNIST 데이터셋에 훈련해보자(keras.datasets.mnist.load_data() 함수를 사용해 데이터를 적재할 수 있다). 또한 최적의 학습률을 찾아보고 체크포인트를 저장하고, 조기종료를 사용하고, 텐서보드를 사용해 학습 곡선을 그려보자.
from tensorflow import keras
(X_train_full,y_train_full),(X_test,y_test)= keras.datasets.mnist.load_data()
X_valid,X_train=X_train_full[:10000]/255.0,X_train_full[10000:]/255.0
y_valid,y_train=y_train_full[:10000],y_train_full[10000:]
X_test=X_test/255.0
import matplotlib.pyplot as plt
plt.imshow(X_train[0],cmap='binary')
plt.axis('off')
plt.show()
검증 세트는 10000개의 이미지를 담고 있고 테스트 세트도 10000개의 이미지를 담고 있다.
import numpy as np
np.unique(y_train)
X_valid.shape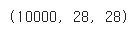
X_train.shape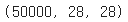
이 데이터셋에 있는 이미지 샘플 몇 개를 출력해 보자.
n_rows=4
n_cols=10
plt.figure(figsize=(n_cols,n_rows))
for row in range(n_rows):
for col in range(n_cols):
index=n_cols * row + col
plt.subplot(n_rows,n_cols,index+1)
plt.imshow(X_train[index],cmap='binary')
plt.axis('off')
plt.title(y_train[index],fontsize=12)
plt.subplots_adjust(wspace=0.2,hspace=0.5)
plt.show()
간단한 밀집 신경망을 만들고 최적의 학습률을 찾아 보자. 반복마다 학습률을 증가시키기 위해 콜백을 사용한다. 이 코백은 반복마다 학습률과 손실을 기록한다.
K=keras.backend
class ExponentialLearningRate(keras.callbacks.Callback):
def __init__(self,factor):
self.factor=factor
self.rates=[]
self.losses=[]
def on_batch_end(self,batch,logs):
self.rates.append(K.get_value(self.model.optimizer.lr))
self.losses.append(logs['loss'])
K.set_value(self.model.optimizer.lr,self.model.optimizer.lr*self.factor)model=keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(10,activation='softmax')
])
작은 학습률 1e-3에서 시작하여 반복마다 0.5%씩 증가한다.
model.compile(loss='sparse_categorical_crossentropy',
optimizer=keras.optimizers.SGD(lr=1e-3),
metrics=['accuracy'])
expon_lr=ExponentialLearningRate(factor=1.005)
모델을 1 에포크만 훈련해 보자.
history=model.fit(X_train,y_train,epochs=1,
validation_data=(X_valid,y_valid),
callbacks=[expon_lr])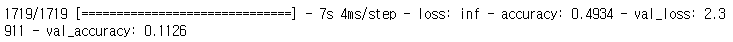
학습률에 대한 함수로 손실을 그릴 수 있다.
plt.plot(expon_lr.rates, expon_lr.losses)
plt.gca().set_xscale('log')
plt.hlines(min(expon_lr.losses), min(expon_lr.rates), max(expon_lr.rates))
plt.axis([min(expon_lr.rates), max(expon_lr.rates), 0, expon_lr.losses[0]])
plt.grid()
plt.xlabel("Learning rate")
plt.ylabel("Loss")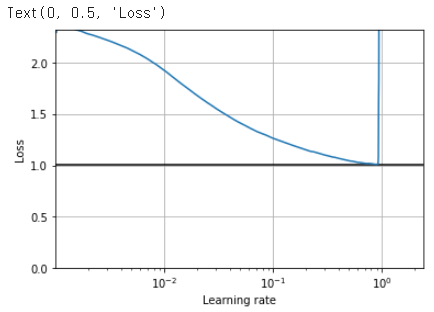
학습률의 loss가 6e-1을 지날 때 갑자기 솟구치기 때문에 3e-1을 학습률로 사용하겠다.
keras.backend.clear_session()
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer=keras.optimizers.SGD(lr=3e-1),
metrics=["accuracy"])
import os
run_index=1
run_logdir=os.path.join(os.curdir,'my_mnist_logs','run_{:03d}'.format(run_index))
run_logdir
early_stopping_cb=keras.callbacks.EarlyStopping(patience=20)
checkpoint_cb=keras.callbacks.ModelCheckpoint('my_mnist_model.h5',save_best_only=True)
tensorboard_cb=keras.callbacks.TensorBoard(run_logdir)
history=model.fit(X_train,y_train,epochs=100,
validation_data=(X_valid,y_valid),
callbacks=[checkpoint_cb,early_stopping_cb,tensorboard_cb])
model=keras.models.load_model('my_mnist_model.h5')
model.evaluate(X_test,y_test)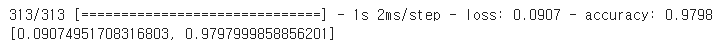
97.98%의 정확도를 얻었다!
마지막으로 텐서보드를 사용해 학습 곡선을 살펴보자.
%tensorboard --logdir=./my_mnist_logs --port=6006
'모델 실습' 카테고리의 다른 글
| tf.keras를 사용한 Neural Style Transfer (0) | 2021.06.16 |
|---|---|
| 5. 심층 신경망 실습 (0) | 2021.06.07 |
| 3. 비지도학습 - 실습 (0) | 2021.05.30 |
| 2. 앙상블 학습과 랜덤 포레스트 - 실습 (0) | 2021.05.22 |
| 1. 서포트 벡터 머신(SVM) 실습 (0) | 2021.05.20 |