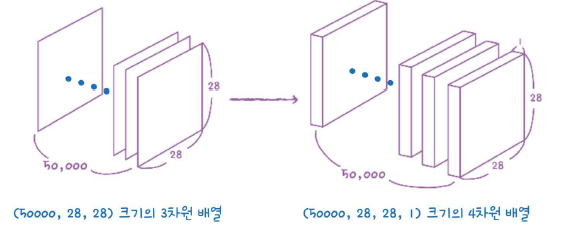
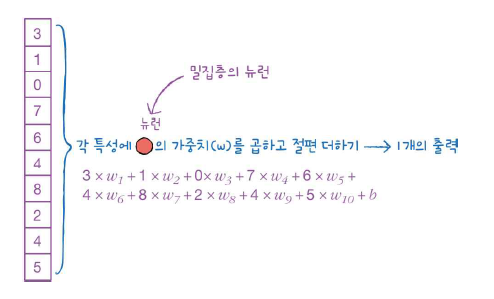
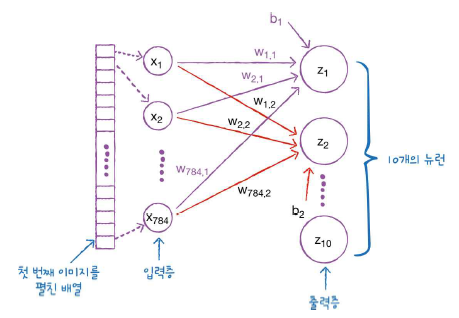
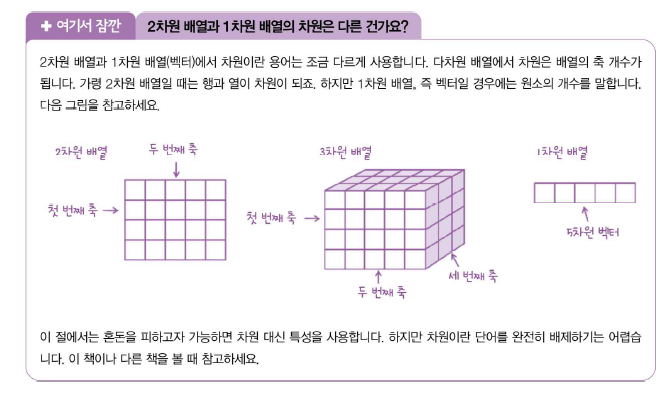
이 포스팅은 밑바닥부터 시작하는 딥러닝을 공부하고 정리한것 입니다. 앞에서 배운 퍼셉트론의 장점은 복잡한 함수를 표현할 수 있다는 것이다. 그러나 단점은 가중치를 설정하는 작업은 여전히 사람이 수동으로 한다는 점이다. 신경망이 이러한 단점을 커버해준다. 가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력이 이제부터 살펴볼 신경망의 중요한 성질이다. 퍼셉트론에서 신경망으로 여기서는 입력,은닉,출력층을 순서대로 0층,1층,2층 이라 하겠다. 그림 3-1의 신경망은 모두 3층으로 구성된다. 가중치를 갖는 층은 2개뿐이기 때문에 2층 신경망이라고 한다. 위 그림에서는 가중치가 b이고 입력이 1인 뉴런이 추가되었다. 이 퍼셉트론의 동작은 x1,x2,1 이라는 3개의 신호가 뉴런에 입력되어, 각 신호..