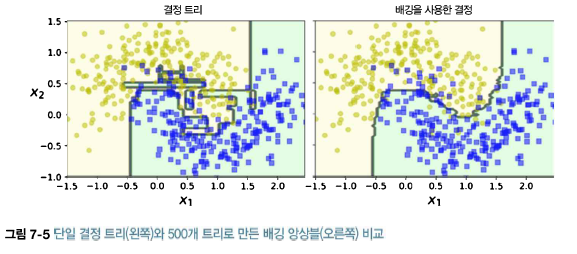
랜덤 포레스트는 일반적으로 배깅 방법(또는 페이스팅)을 적용한 결정 트리의 앙상블이다. 전형적으로 max_samples를 훈련 세트의 크기로 지정한다. BaggingClassifier에 DecisionTreeClassifier를 넣어 만드는 대신 결정 트리에 최적화되어 사용하기 편리한 RandomForestClassifier를 사용할 수 있다.(비슷하게 회귀 문제를 위한 RandomForestRegressor 가 있다). 다음은 최대 16개의 리프 노드를 갖는 500개 트리로 이뤄진 랜덤 포레스트 분류기를 여러 CPU코어에서 훈련 시키는 코드이다. from sklearn.ensemble import RandomForestClassifier rnd_clf=RandomForestClassifier(n_est..