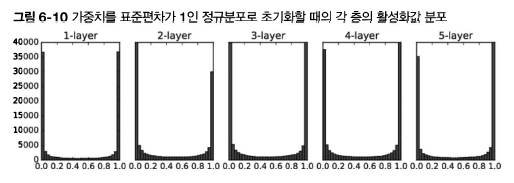
이 포스팅은 밑바닥부터 시작하는 딥러닝을 공부하고 정리한것 입니다. 기계학습에서는 오버피팅이 문제가 되는 일이 많다. 오버피팅이란 신경망이 훈련 데이터에만 지나치게 적응되어 그 외의 데이터에는 제대로 대응하지 못하는 상태를 말한다. 1. 오버피팅 오버피팅은 주로 다음의 두 경우에 일어난다 1. 매개변수가 많고 표현력이 높은 모델 2. 훈련 데이터가 적음 이처럼 정확도가 크게 벌어지는 것은 훈련 데이터에만 적응(fitting)해버린 결과이다. 훈련 때 사용하지 않은 범용 데이터에는 제대로 대응하지 못하는 것을 이 그래프에서 확인할 수 있다. 2. 가중치 감소 오버피팅 억제용으로 예로부터 많이 이용해온 방법 중 가중치 감소(weight decay)라는 것이 있다. 이는 학습 과정에서 큰 가중치에 대해서는 그..