https://www.kaggle.com/alessiocorrado99/animals10
Animals-10
Animal pictures of 10 different categories taken from google images
www.kaggle.com
10개의 클래스를 가진 동물 이미지를 분류하는 방법에 대해 정리한 글이다.
먼저 필요한 모듈들을 import 해준다.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
import torch
import torchvision
from torchvision import datasets,models,transforms
import matplotlib.pyplot as plt
import torch.nn as nn
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
path,folder=os.path.split(dirname)
- data augment 처리
train_on_gpu=torch.cuda.is_available()
data_transform1=transforms.Compose([transforms.RandomRotation(45),
transforms.RandomRotation(30),
transforms.RandomResizedCrop(1080),
transforms.Resize(512),
transforms.Resize(224),
transforms.RandomRotation(45),
transforms.ToTensor()])
data_transform2=transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(1080),
transforms.Resize(224),
transforms.RandomRotation(45),
transforms.RandomRotation(35),
transforms.ToTensor()])
- data 읽기
우선 이미지 크기를 동일하게 해야 하기 때문에 각 클래스별로 750개의 이미지를 픽업할 것이다. torch loader에 data를 로딩하기 전에 train,validation,test로 나눠야 한다. numpy를 사용해서 나눌것이고 random shuffle을 사용해 image_folder로부터 랜덤한 images를 얻을것이다.
print('path:',path)
print('folder:',folder)
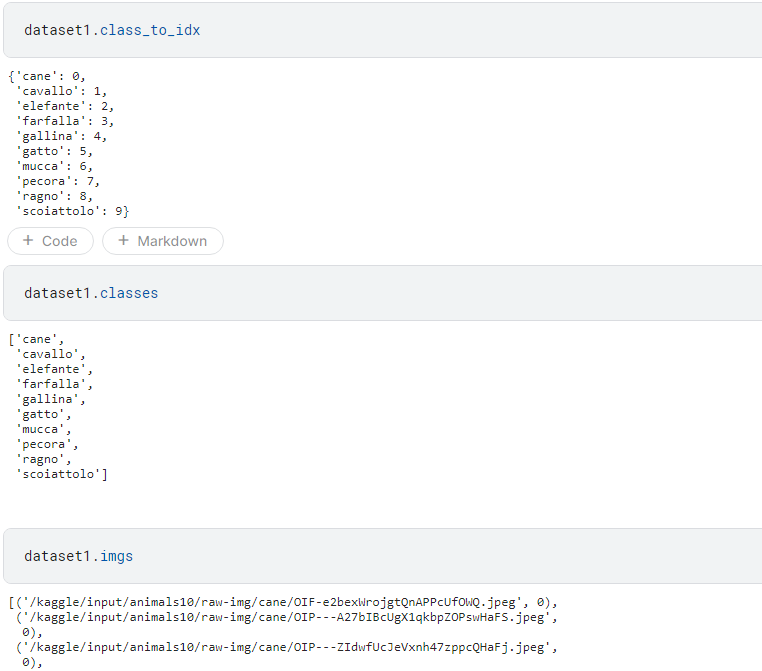
ImageFolder 객체를 사용하면 path 위치에서 존재하는 하위폴더들의 이름을 classes로, 하위폴더 안에 있는 이미지들을 imgs로 참조할 수 있게 만들어 준다.
from torch.utils.data import Subset,ConcatDataset,DataLoader
dataset1=datasets.ImageFolder(path,transform=data_transform1)
dataset2=datasets.ImageFolder(path,transform=data_transform2)
print(type(dataset1))
maxlen=750
for l,cls in enumerate(dataset1.classes):
if l==0:
idx=[i for i in range(len(dataset1)) if dataset1.imgs[i][1] == dataset1.class_to_idx[dataset1.classes[l]]]
# idx는 결국 같은 클래스를 보유한 이미지들만 모으기 위한 수단이다.
subset=Subset(dataset1,idx)
master=Subset(subset,idx[:maxlen])
subset=Subset(dataset2,idx[:maxlen])
master=ConcatDataset((master,subset))
print(len(master))
else:
idx=[i for i in range(len(dataset1)) if dataset1.imgs[i][1] == dataset1.class_to_idx[dataset1.classes[l]]]
subset=Subset(dataset1,idx[:maxlen])
master=ConcatDataset((master,subset))
subset=Subset(dataset2,idx[:maxlen])
master=ConcatDataset((master,subset))
print(len(master))
- VGG19 load
classifier 부분만 다음과 같이 수정해준다.
from collections import OrderedDict
model=models.vgg19(pretrained=True)
classifier=nn.Sequential(OrderedDict([('fc1',nn.Linear(25088,6000)),
('relu',nn.ReLU()),
('fc2',nn.Linear(6000,10)),
('output',nn.Softmax(dim=1))]))
model.classifier=classifier
print(model)'fc1'의 25088은 512 x 7 x 7 에 의해 나온 숫자이다.
import torch.optim as optim
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.001)
- Training
def seq(model,df,name):
train_loss= 0.0
class_correct=list(0. for i in range(10))
class_total=list(0. for i in range(10))
for batch_i,(data,target) in enumerate(df):
# move tensors to GPU if CUDA is available
if train_on_gpu:
data,target=data.cuda(),target.cuda()
model.cuda()
# clear the gradients of all optimized variables
optimizer.zero_grad()
# forward pass: compute predicted outputs by passing inputs to the model
output=model(data)
# calculate the batch loss
loss=criterion(output,target)
# backward pass: computer gradient of the loss with respect to model parameters
if name=='train':
loss.backward()
# perform a single optimization step(parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()
_,pred=torch.max(output,1)
# compare predictions to true label
correct_tensor=pred.eq(target.data.view_as(pred))
correct=np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy())
for i in range(len(target.data)):
label=target.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
return class_correct,class_total,train_loss
예측값 pred와 target.data(원래 라벨)을 비교해서 맞춘 것은 True, 틀리면 False를 반환하는 correct_tensor를 구한다. 그후 축을 제거해(1인 축) correct 리스트로 만들고 class_correct[label]에 이 값이 False면 0을 더하고 True면 1을 더한다.
class_total은 target.data를 조회할때마다 1을 더해 총 숫자를 계산한다.
- print data function
def printdata(class_correct,class_total,train_loss,epoch,name,df):
print(f'Epoch %d, loss: %.8f \t{name} Accuracy (Overall): %2d%% (%2d/%2d)' %(epoch,
train_loss/len(df), 100.*np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct),np.sum(class_total)))
if ((epoch+1) % 5 ==0 or epoch==1):
for i in range(10):
if class_total[i] > 0 :
print(f'{name} Accuracy of %5s: %2d%% (%2d/%2d)' %(
translate[classes[i]], 100 * class_correct[i] / class_total[i],
np.sum(class_correct[i]),np.sum(class_total[i])))
- model train function
def trainModel(model, train_loader,valid_loader,num_epochs=20):
n_epochs=num_epochs
for epoch in range(1,n_epochs + 1):
train_loss=0.0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
model.train()
class_correct,class_total,train_loss=seq(model,train_loader,'train')
printdata(class_correct,class_total,train_loss,epoch,'train',train_loader)
model.eval()
class_correct,class_total,train_loss=seq(model,valid_loader, 'validation')
printdata(class_correct,class_total,train_loss,epoch,'validation',valid_loader)
torch.save(model.state_dict(),'model.pt')
print(f'model saved')
print(len(train_loader),len(valid_loader))
trainModel(model, train_loader,valid_loader,80)
- testing the model
test_loss=0.0
class_correct=list(0. for i in range(10))
class_total=list(0. for i in range(10))
model.eval()
class_correct,class_total,train_loss=seq(model,test_loader,'test')
printdata(class_correct,class_total,train_loss,1,'test',test_loader)
# obtain one batch of test images
dataiter=iter(test_loader)
images,labels=dataiter.next()
images.numpy()
# move model inputs to cuda, if GPU available
if train_on_gpu:
images,labels=images.cuda(), labels.cuda()
print('train on gpu',train_on_gpu)
# get sample outputs
output=model(images)
images=images.cpu()
# convert output probabilities to predicted class
_,preds_tensor=troch.max(output,1)
preds=np.squeeze(preds_tensor_numpy()) if not train_on_gpu else np.squeeze(preds_tensor.cpu().numpy())
fig=plt.figure(figsize=(25,4))
for idx in np.arange(disimage):
ax=fig.add_subplot(2,disimage/2,idx+1)
plt.imshow(np.transpose(images[idx],(1,2,0)))
ax.set_title('{} ({})'.format(translate[classes[preds[idx]]],translate[classes[labels[idx]]]),
color=('green' if preds[idx] == labels[idx].item() else 'red'))
'Kaggle' 카테고리의 다른 글
| Digit-recognizer (0) | 2021.07.11 |
|---|---|
| 이미지 분류(이진 분류) (0) | 2021.07.06 |
| notMNIST (0) | 2021.06.13 |