https://www.kaggle.com/olavomendes/cars-vs-flowers
cars_vs_flowers
Dataset with pictures of cars and flowers
www.kaggle.com
두가지 레이블만 존재하는 데이터셋이다. 두가지 레이블이기 때문에 이진 분류를 사용하겠다.
먼저 다운로드 받은 데이터를 코랩에서 압축해제한다.
!unzip -qq '/content/drive/MyDrive/archive (1).zip'import os
import cv2
import matplotlib.pyplot as plt각각 레이블의 트레이닝 이미지가 몇장인지 계산한다.
len(os.listdir('/content/dataset/cars_vs_flowers/training_set/car'))
len(os.listdir('/content/dataset/cars_vs_flowers/training_set/flower'))
두 레이블 모두 1000장의 이미지가 있다.
이미지의 파일 정보를 알아보자.
from PIL import Image
im=Image.open('/content/dataset/cars_vs_flowers/training_set/car/f0002b05b35a53e3.jpg')
print(im.format,im.size,im.mode)
car 폴더와 flower 폴더의 directory를 저장한다.
car_dir=os.path.join('/content/dataset/cars_vs_flowers/training_set/car')
flower_dir=os.path.join('/content/dataset/cars_vs_flowers/training_set/flower')
어떤 이미지가 들어있는지 확인해보자.
import matplotlib.image as mpimg
img=mpimg.imread(os.path.join(car_dir,car_files[0]))
# img=cv2.imread(os.path.join(car_dir,car_files[0]))
plt.imshow(img)
plt.axis('off')
plt.show()
두 폴더의 사진들을 합치고 레이블을 부여한다.
x=[]
y=[]
for i in range(1000):
img=cv2.imread(os.path.join(car_dir,car_files[i]))
(b, g, r)=cv2.split(img)
img=cv2.merge([r,g,b])
# cv2 함수를 사용하면 텐서플로에서 오류가 발생하지 않는다
img_data=np.asarray(img,dtype=np.int16)
x.append(img_data)
y.append(0)
img=cv2.imread(os.path.join(flower_dir,flower_files[i]))
(b, g, r)=cv2.split(img)
img=cv2.merge([r,g,b])
img_data=np.asarray(img,dtype=np.int16)
x.append(img_data)
y.append(1)
x=np.asarray(x).reshape(2000,128,128,3)x.shape
데이터를 섞기 위해 데이터와 레이블을 하나의 그룹으로 묵고 섞는다. 그다음 다시 나눈다.
temp=list(zip(x,y))
np.random.shuffle(temp)
x,y=zip(*temp)
x,y=np.asarray(x),np.asarray(y)
x=x/255.0
p=0.9
num_train=int(2000 * p)
x_train,x_test=x[:num_train],x[num_train:]
y_train,y_test=y[:num_train],y[num_train:]
모델을 구성한다.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Reshape,Flatten,Conv2D,MaxPooling2D,Dropout,Dense
from tensorflow.keras.models import Sequential
model=Sequential([
Conv2D(64,3,activation='relu',input_shape=(128,128,3)),
MaxPooling2D(2,2),
Conv2D(128,3,activation='relu'),
MaxPooling2D(2,2),
Flatten(),
Dropout(0.5),
Dense(128,activation='relu'),
Dense(1,activation='sigmoid')
])model.summary()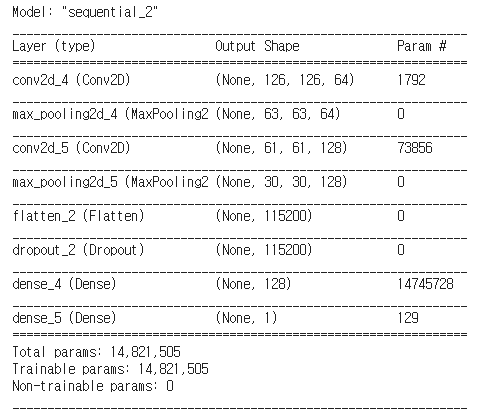
텐서보드를 이용하기위해 다음 코드를 작성한다.
root_logdir=os.path.join(os.curdir,'my_logs')
def get_run_logdir():
import time
run_id=time.strftime('run_%Y_%m_%d_%H_%M_%S')
return os.path.join(root_logdir,run_id)
run_logdir=get_run_logdir()
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
tensorboard_cb=keras.callbacks.TensorBoard(run_logdir)
model.fit(x_train,y_train,
epochs=30,batch_size=64,
callbacks=[tensorboard_cb])
model.save('font_basic.h5')%load_ext tensorboard
%tensorboard --logdir=./my_logs --port=6006
score=model.evaluate(x_test,y_test,verbose=False)
print('loss',score[0])
print('accuracy',score[1]*100)
정확도가 아쉽다. 파라미터를 조정해봐야겠다.
'Kaggle' 카테고리의 다른 글
| Animal - 10 분류 - pytorch (0) | 2021.11.27 |
|---|---|
| Digit-recognizer (0) | 2021.07.11 |
| notMNIST (0) | 2021.06.13 |