이번 포스팅에서는 신경망을 깊이 관점이 아닌 너비 관점으로 해석한 논문인 Wide Residual Networks를 리뷰해 보겠다.
Abstract
Deep residual network는 수천 층으로 scale up 될수 있음을 보여주었고, 여전히 성능을 향상시키고 있다. 그러나 층이 깊어질수록 훈련 속도가 느려진다. 이러한 문제를 다루기 위해, 이 논문에서는 ResNet block의 구조에대해 자세한 실험을 했고 이들은 residual network의 깊이는 줄이고 너비를 늘렸다. 이들은 이러한 구조를 wide residual network(WRNs)라고 하고 이 구조가 일반적으로 사용되는 얇고 매우 깊은 네트워크보다 훨씬 우수하다는 것을 보여주었다. 예를 들어서 이들의 16층 wide residual network는 정확도와 효율성에서 이전의 모든 deep residual network의 성능을 능가했다.
신경망의 너비를 증가시킨다는 것은 filter수를 증가시킨다는 의미이다. 즉, WRN은 residual block을 구성하는 convolution layer의 filter 수를 증가시켜서 신경망의 넓이를 증가시켰다.
Introduction
CNN은 지난 몇년간 층의 깊이를 증가시켰다. 그러나 깊은 신경망을 훈련시키는 것은 exploding/vanishing gradient and degradation같은 몇몇 어려움이 있었다. 깊은 구조와 얕은 구조는 기계학습에서 오랫동안 논의되어 왔으며, 얕은 신경망은 깊은 신경망보다 기하급수적으로 더 많은 구성요소를 필요로한다. 매우 깊은 네트워크를 훈련할 수 있는 identity mapping이 있는 residual block은 동시에 residual network의 약점이라는 것에 이들은 주목했다. 대신 이들은 ResNet의 block를 넓히는 것이 깊이를 증가시키는 것보다 성능을 향상시키는데 더 효율적인 방법을 제공한다는 것을 보였다.
또한 residual blocks 를 넓히면 파라미터의 수가 증가하게 되는데 이들은 이 문제를 해결하기 위해 dropout을 사용했다. 이들은 dropout을 합성곱층 사이에 넣었다.
결론적으로 이들의 Wide ResNet은 최첨단의 성능을 몇몇 dataset에서 냈고 정확도와 속도가 극적으로 향상되었다.
Wide Residual Network

이들은 기존 구조의 순서인 Conv-BN-ReLU가 아닌 BN-ReLU-Conv로 순서를 변경했다. 후자가 더 빨리 훈련하고 좋은 결과를 냈다. residual block의 power를 향상시킬수 있는 간단한 3가지 필수적인 방법은 다음과 같다.
1. 합성곱층을 block마다 더 추가한다.
2. feature planes를 더 추가하면서 합성곱층의 너비를 넓힌다.
3. 합성곱층의 필터 size를 증가시킨다.
작은 필터가 성능이 좋다는것이 이미 연구되었기 떄문에 이들은 3x3필터보다 더 큰 필터는 사용하지 않았다.
이 논문에서 깊이 factor는 l, 너비 factor는 k로 나타냈다. figure1(a),(c)는 basic 모델과 basic-wide모델의 예를 보여준다.
논문 저자들의 residual network의 일반적인 구조는 표1에 설명되어있다.
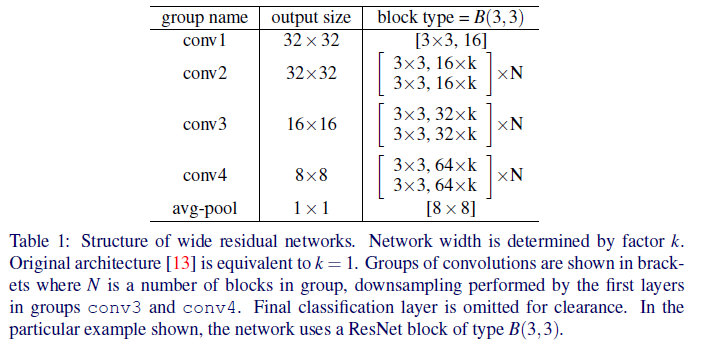
width of residual blocks
깊이(l)나 resnet block의수(d)가 증가할때 파라미터의 수는 선형적으로 증가하는 반면 k는 네배 증가하게 된다. 하지만, GPU가 대형 텐서에서의 병렬 연산에 훨씬 효율적이기 때문에 수천 개의 작은 커널보다 층을 넓히는 것이 계산적으로 더 효과적이어서 이들은 d to k 비율에 더 관심을 가졌다.
논문 저자들은 k=1인 원래 residual network를 thin network, k>1인 네트워크를 wide 네트워크라고 한다. 본 논문의 나머지 부분에서는 다음과 같은 표기법을 사용한다: WRN-n-k는 총 합성곱층 n과 너비 인자 k를 갖는 residual network를 나타낸다(예를들어, 원래보다 40개의 층과 k=2배 넓은 network를 WRN-40-2로 표시한다).
Dropout in residual Network
fig1(d) 처럼 dropout층을 넣었다.
Experimental results
(1) Type of convolutions in a block
residual blcok을 구성하는 conv layer 개수와 kernel_size에 따른 성능 실험이다. 예를 들어, B(1,3,1)은 1x1conv, 3x3conv, 1x1conv로 이루어진 residual block이다.

(2) Number of convolutions per block
table3는 블록당 합성곱층수의 수에 따른 에러율을 나타내는 WRN-40-2를 보여준다.
(3)width of residual blocsk
table4에 k와 깊이의 비율에 대한 에러율이 나타나 있다. 여기서 볼 수 있듯이 깊이는 28이고, k=10일때 가장 효율적인 모델인것 같다. 또한 table5를 보면 얇거나 넓은 residual network를 비교한 부분을 볼 수 있는데 WRN-40-4는 ResNet-1001보다 더 나은 성능을 보여준다. 이 두 모델의 파라미터 수는 각각 8.9M과 10.2M인데 이는 깊이가 이 수준에서 너비에 비해 정규화 효과를 추가하지 않음을 보여준다.
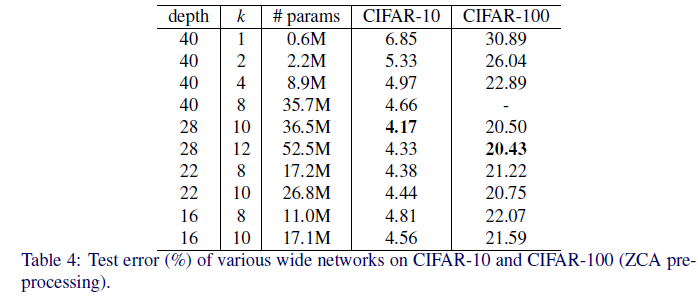
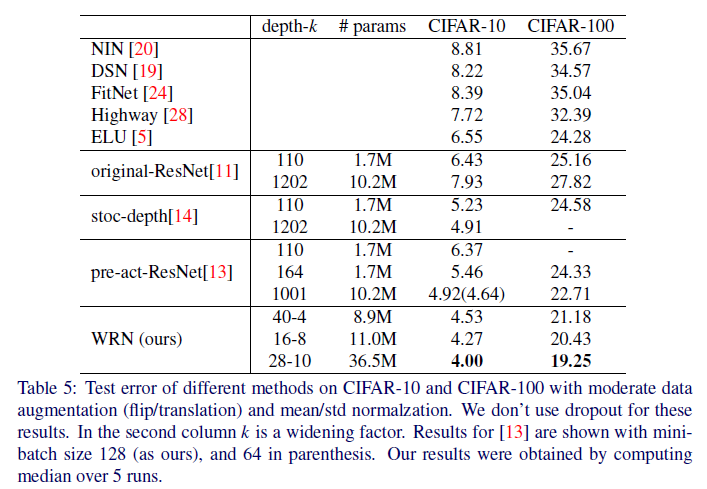
깊이는 정규화 효과를 일으키고, 너비는 과적합을 일으킨다는 이전의 주장에도 불구하고, 이들은 ResNet-1001보다 몇 배 더 많은 매개변수를 가진 네트워크를 성공적으로 교육시켰다. 예를 들어, 와이드 WRN-28-10과 WRN-40-10은 각각 ResNet-1001보다 3.6, 5배 더 많은 매개변수를 가지고 있으며, 둘 다 상당한 차이로 이를 능가한다.
요약하자면
1. widening은 여러 깊이의 residual network에서 성능을 일관되게 향상시킨다.
2. 깊이와 너비 둘다 증가시키는것은 파라미터의 수가 너무 많아지거나 강한 regularization이 필요해지기 전까지는 도움이 된다.
3. 얇은 신경망과 동일한 수의 매개변수를 가진 넓은 신경망이 동일하거나 더 나은 성능을 낼 수 있기 때문에 residual network의 매우 깊은 깊이는 정규화 효과가 없는 것으로 보인다. 더군다나, wide network는 얇은 네트워크보다 2배 이상의 많은 수의 매개변수를 사용하여 성공적으로 학습할 수 있다.
'논문 리뷰, 구현' 카테고리의 다른 글
| 10. ResNeXt 리뷰, 구현 (0) | 2022.07.05 |
|---|---|
| 8. SqueezeNet 논문 리뷰, 구현 (0) | 2022.07.03 |
| 7. DenseNet 논문 리뷰,구현 (0) | 2022.07.03 |
| 6. ResNet 논문 리뷰, 구현 (0) | 2022.07.03 |
| 5.Network in Network 논문 리뷰 (0) | 2022.07.03 |