이번 포스팅에서는 EAST detector를 이용해서 image 안에 있는 글씨를 인식하고 tesseract로 어떤 글씨인지 읽어오는 프로젝트에 대해 소개하겠다.
OpenCV의 EAST text detector는 새로운 아키텍처와 학습 패턴을 기반으로 한 딥러닝 모델이다. 이것은 720p image에서 13FPS의 거의 real-time에 가까운 성능을 보여주고, 최첨단의 text 검출 정확도를 얻게해준다.
프로젝트를 하면서 글씨를 인식하는데 주위 빛, 조명 글씨의 정성도 등이 검출하는데 매우 중요한 역할을 한다는 것을 알게 되었다.
먼저 필요한 module들을 import 해주고 상수, path를 지정해준다.
from imutils.object_detection import non_max_suppression
import numpy as np
import time
import cv2
import pytesseract
file_name='image/text_image_01.png'
east='frozen_east_text_detection.pb'
min_confidence=0.5
width=320
height=320
여기서 중요한 부분이 있는데 EAST detector는 input image의 size가 32의 배수여야 한다.
# load the input image and grab the image dimensions
image=cv2.imread(file_name)
orig_image=image.copy()
text_extract_image=image.copy()
(H,W) = image.shape[:2]
# 새로운 width와 height를 설정하고 비율을 구한다
(newW,newH) = width,height
rW=W/float(newW)
rH=H/float(newH)
# image의 size를 재설정하고 새 이미지의 dimension을 구한다
image=cv2.resize(image,(newW,newH))
(H,W) = image.shape[:2]
EAST detector model의 2개의 output층을 정의한다.
첫번째 층은 output sigmoid activation인데 지역이 text를 포함하는지 안하는지에 관련된 확률을 준다.
두번째 층은 text의 bounding box 좌표를 추출하는데 사용된다.
layerNames=[
'feature_fusion/Conv_7/Sigmoid',
'feature_fusion/concat_3'
]
다음 코드들은 주석으로 설명하겠다.
# load the pre-trained EAST text detector
print('[INFO] loading EAST text detector...')
net=cv2.dnn.readNet(east)
blob=cv2.dnn.blobFromImage(image,1.0,(H,W),
(123.68,116.78,103.94),swapRB=True,crop=False)
start=time.time()
net.setInput(blob)
# geometry는 우리의 input image로 부터 bounding box좌표를 얻게해준다
# scores는 주어진 지역에 text가 있는지에 대한 확률을 준다
(scores,geometry) = net.forward(layerNames)
end=time.time()
print('[INFO] text detection took {:.6f} seconds'.format(end-start))
# scores의 크기를 받고 bounding box 사각형을 추출한뒤 confidencs scores에 대응해본다
(numRows,numCols) = scores.shape[2:4]
rects=[]
confidences=[]for y in range(0,numRows):
scoresData=scores[0,0,y]
xData0=geometry[0,0,y]
xData1=geometry[0,1,y]
xData2=geometry[0,2,y]
xData3=geometry[0,3,y]
anglesData=geometry[0,4,y]
for x in range(0,numCols):
# 만약 score가 충분한 확률을 가지고 있지 않다면 무시한다
if scoresData[x] < min_confidence:
continue
# 우리의 resulting feature map은 input_image보다 4배 작을것 이기 때문에
# offset factor를 계산한다
(offsetX,offsetY) = (x*4.0,y*4.0)
# prediciton에 대한 회전각을 구하고 sin,cosine을 계산한다
# 글씨가 회전되어 있을때를 대비
angle=anglesData[x]
cos=np.cos(angle)
sin=np.sin(angle)
# geometry volume를 사용해 bounding box의 width 와 height를 구한다
h=xData0[x] + xData2[x]
w=xData1[x] + xData3[x]
# text prediction bounding box의 starting, ending (x,y) 좌표를 계산한다
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
# bounding box coordinates와 probability score를 append한다
rects.append((startX,startY,endX,endY))
confidences.append(scoresData[x])
다음 코드는 불필요한 bounding box를 제거하기 위해 매우 중요한 코드이다.
# non-maxima suppression 을 weak,overlapping bounding boxes을 없애기위해 적용해준다
boxes=non_max_suppression(np.array(rects),probs=confidences)
다음 코드는 pytesseract를 이용해 text를 읽어오는 함수이다.
def textRead(image):
# apply Tesseract v4 to OCR
config = ("-l eng --oem 1 --psm 7")
text = pytesseract.image_to_string(image, config=config)
# display the text OCR'd by Tesseract
print("OCR TEXT : {}\n".format(text))
# strip out non-ASCII text
text = "".join([c if c.isalnum() else "" for c in text]).strip()
print("Alpha numeric TEXT : {}\n".format(text))
return text
다음 코드는 NMS를 처리한 유의미한 bounding box를 이용해 text image만 추출한뒤 text를 읽어온다. 그다음 orig_image에 bounding box와 text를 표시해준다.
for (startX,startY,endX,endY) in boxes:
# 앞에서 구한 비율에 따라서 bounding box 좌표를 키워준다
startX=int(startX * rW)
startY=int(startY * rH)
endX=int(endX * rW)
endY=int(endY * rH)
text=textRead(text_extract_image[startY:endY, startX:endX])
cv2.rectangle(orig_image,(startX,startY),(endX,endY),(0,255,0),2)
cv2.putText(orig_image, text, (startX, startY-10),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3)
cv2.imshow('Text Detection', orig_image)
cv2.waitKey(0)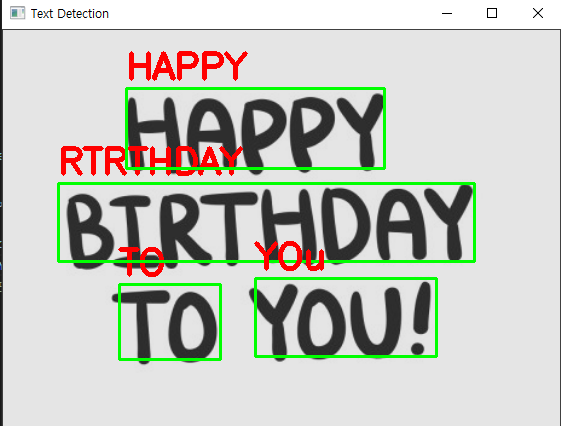
'Object Detection' 카테고리의 다른 글
| 자동차 번호판 인식 프로젝트 (0) | 2021.09.03 |
|---|---|
| 직접 쓴 손 글씨(숫자) 인식하기 - 글씨 추출 및 검출 (0) | 2021.08.27 |
| 직접 쓴 손 글씨(숫자) 인식하기 - 필터링을 통한 인식률 향상시키는 방법 (0) | 2021.08.26 |
| object detection project - keras를 사용한 detection(2) (0) | 2021.08.26 |
| object detection project - keras를 사용한 detection(1) (0) | 2021.08.24 |