SVM을 분류가 아니라 회귀에 적용하는 방법은 목표를 반대로 하는 것이다. 일정한 마진 오류 안에서 두 클래스 간의 도로 폭이 가능한 한 최대가 되도록 하는 대신, SVM 회귀는 제한된 마진 오류(즉, 도로 밖의 샘플) 안에서 도로 안에 가능한 한 많은 샘플이 들어가도록 학습한다. 도로의 폭은 하이퍼파라미터 e(입실론)으로 조절한다.
다음 그림은 무작위로 생성한 선형 데이터셋에 훈련시킨 두 개의 선형 SVM 회귀 모델을 보여준다. 하나는 마진을 크게(e=1.5)하고 다른 하나는 마진을 작게(e=0.5)하여 만들었다.
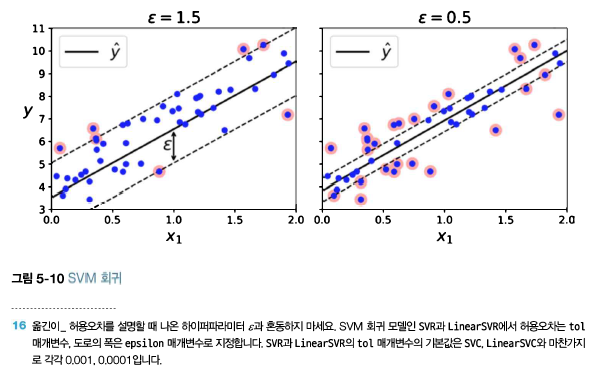
마진 안에서는 훈련 샘플이 추가되어도 모델의 예측에는 영향이 없다. 그래서 이 모델을 e에 민감하지 않다 라고 한다.
사이킷런의 LinearSVR을 사용해 선형 SVM 회귀를 적용해보겠다. 다음 코드는 그림 5-10의 왼쪽 그래프에 해당하는 모델을 만든다. (먼저 훈련 데이터의 스케일을 맞추고 평균을 0으로 맞춰야 한다)
from sklearn.svm import LinearSVR
svm_reg=LinearSVR(epsilon=1.5)
svm_reg.fit(X,y)비선형 회귀 작업을 처리하려면 커널 SVM 모델을 사용한다. 다음 그림은 임의의 2차방정식 형태의 훈련 세트에 2차 다항 커널을 사용한 SVM 회귀를 보여준다. 왼쪽 그래프는 규제가 거의 없고(즉, 아주 큰 C), 오른쪽 그래프는 규제가 훨씬 많다(즉, 작은 C).

다음 코드는 (커널 트릭을 제공하는) 사이킷런의 SVR을 사용해 5-11의 왼쪽 그래프에 해당하는 모델을 만든다.
from sklearn.svm import SVR
svm_poly_reg=SVR(kernel='poly',degree=2,C=100,epsilon=0.1)
svm_poly_reg.fit(X,y)
'Machine Learning > Advanced (hands on machine learning)' 카테고리의 다른 글
| 17. 결정 트리 - 클래스 확률 추정, CART 훈련 알고리즘, 계산 복잡도 (0) | 2021.05.21 |
|---|---|
| 16. 결정 트리 - 결정 트리 학습과 시각화, 예측 (0) | 2021.05.21 |
| 13. 서포트 벡터 머신 - 비선형 SVM 분류 (0) | 2021.05.19 |
| 12. 서포트 벡터 머신 - 선형 SVM 분류 (0) | 2021.05.19 |
| 11. 모델 훈련 - 로지스틱 회귀 (0) | 2021.05.19 |