이 포스팅은 혼자 공부하는 머신러닝 + 딥러닝을 공부하고 정리한것 입니다.
지금까지 k-최근접 이웃, 선형 회귀, 릿지, 라쏘, 다항회귀, 로지스틱 회귀를 배웠고 확률적 경사 하강법 알고리즘을 사용한 분류기와 결정 트리 모델까지 공부했다. 테스트세트 사용 없이 모델의 성능을 평가하는 교차 검증과 하이퍼 파라미터 튜닝까지 공부했다.
지금까지 배운 머신러닝 알고리즘은 정형 데이터에 잘 맞는다. 그중에 정형 데이터를 다루는 데 가장 뛰어난 성과를 내는 알고리즘이 앙상블 학습(ensemble learning)이다. 이 알고리즘은 대부분 결정 트리를 기반으로 만들어져 있다. 이제 사이킷런에서 제공하는 정형 데이터의 끝판왕인 앙상블 학습 알고리즘을 알아보겠다.
랜덤 포레스트
랜덤 포레스트(Random Forest)는 앙상블 학습의 대표 주자 중 하나로 안정적인 성능 덕분에 널리 사용되고 있다. 랜덤 포레스트는 결정 트리를 랜덤하게 만들어 결정 트리(나무)의 숲을 만든다. 그리고 각 결정 트리의 예측을 사용해 최종 예측을 만든다.

랜덤 포레스트는 각 트리를 훈련하기 위해서 데이터를 랜덤하게 만드는데 우리가 입력한 훈련 데이터에서 랜덤하게 샘픙을 추출하여 훈련 데이터를 만든다. 이때 한 샘플이 중복되어 추출될 수도 있다. 예를 들어 1000개 가방에서 100개씩 샘플을 뽑는다면 1개를 뽑고, 뽑았던 1개를 다시 가방에 넣는다. 이런 식으로 계속해서 100개를 가방에서 뽑으면 중복된 샘플을 뽑을 수 있다. 이렇게 만들어진 샘플을 부트스트랩 샘플(bootstrap sample)이라고 부른다. 1000개 가방에서 중복하여 1000개의 샘플을 뽑기 때문에 부트스트랩 샘플은 훈련 세트와 크기가 같다.
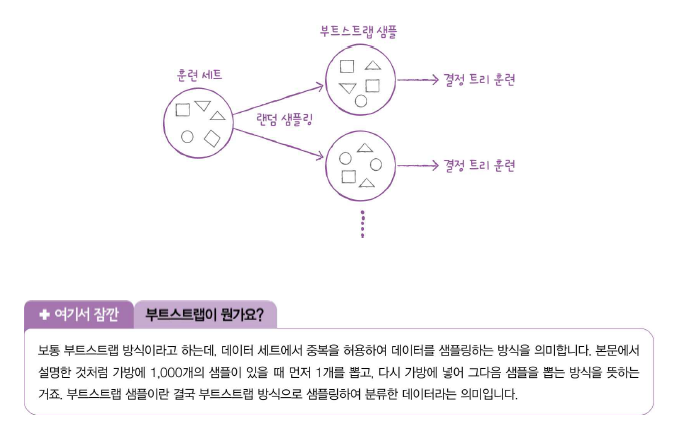
또한 각 노드를 분할할 때 전체 특성 중에서 일부 특성을 무작위로 고른 다음 이 중에서 최선의 분할을 찾는다. 분류 모델인 RandomForestClassifier는 기본적으로 전체 특성 개수의 제곱근만큼의 특성을 선택한다. 다만 회귀 모델인 RandomForestRegressor는 전체 특성을 사용한다.

사이킷런의 랜덤 포레스트는 기본적으로 100개의 결정 트리를 이런 방식으로 훈련한다. 그다음 분류일 때는 각 트리의 클래스별 확률을 평균하여 가장 높은 확률을 가진 클래스를 예측으로 삼는다. 회귀일 때는 단순히 각 트리의 예측을 평균한다.
랜덤 포레스트는 랜덤하게 선택한 샘플과 특성을 사용하기 때문에 훈련 세트에 과대적합되는 것을 막아주고 검증 세트와 테스트 세트에서 안정적인 성능을 얻을 수 있다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine=pd.read_csv('https://bit.ly/wine-date')
data=wine[['alcohol','sugar','pH']].to_numpy()
target=wine['class'].to_numpy()
train_input,test_input,train_target,test_target=train_test_split(data,target,test_size=0.2,random_state=42)
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf=RandomForestClassifier(n_jobs=-1,random_state=42)
scores=cross_validate(rf,train_input,train_target,return_train_score=True,n_jobs=-1)
print(np.mean(scores['train_score']),np.mean(scores['test_score']))

출력된 결과를 보면 훈련 세트에 다소 과대적합된 것 같다.
랜덤 포레스트는 결정 트리의 앙상블이기 때문에 DecisionTreeClassifier가 제공하는 중요한 매개변수를 모두 제공한다. criterion,max_depth,max_features,min_samples_split,min_inpurity_decrease,min_samples_leaf 등이다. 또한 결정 트리의 큰 장점 중 하나인 특성 중요도를 계산한다. 랜덤 포레스트의 특성 중요도는 각 결정 트리의 특성 중요도를 취합한 것이다.
rf.fit(train_input,train_target)
print(rf.feature_importances_)
랜덤 포레스트가 특성의 일부를 랜덤하게 선택하여 결정 트리를 훈련하기 때문에 그 결과 하나의 특성에 과도하게 집중하지 않고 좀 더 많은 특성이 훈련에 기여할 기회를 얻는다. 이는 과대적합을 줄이고 일반화 성능을 높이는 데 도움이 된다.
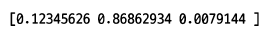
RandomForestClassifier에는 자체적으로 모델을 평가하는 점수를 얻을 수 있다. 랜덤 포레스트는 훈련 세트에서 중복을 허용하여 부트스트랩 샘플을 만들어 결정 트리를 훈련한다 했다. 이때 부트스트랩 샘플에 포함되지 않고 남는 샘플이 있는데 이런 샘플을 OOB(out of bag) 샘플이라 한다. 이 남는 샘플을 사용하여 부트스트랩 샘플로 훈련한 결정 트리를 평가할 수 있다. oob_score 매개변수를 True로 지정해야 랜덤 포레스트는 각 결정 트리의 OOB 점수를 평균하여 출력한다.
rf=RandomForestClassifier(oob_score=True, n_jobs=-1,random_state=42)
rf.fit(train_input,train_target)
print(rf.oob_score_)
교차 검증에서 얻은 점수와 매우 비슷한 결과를 얻었다. OOB 점수를 사용하면 교차 검증을 대신할 수 있어서 결과적으로 훈련 세트에 더 많은 샘플을 사용할 수 있다.
'Machine Learning > Basic' 카테고리의 다른 글
| [6-1] 군집 알고리즘 (0) | 2021.04.13 |
|---|---|
| [5-3-(2)] 트리의 앙상블 - 엑스트라 트리, 그레이디언트 부스팅, 히스토그램 기반 그레이디언트 부스팅 (0) | 2021.04.10 |
| [5-2] 교차 검증과 그리드 서치 (0) | 2021.04.07 |
| [5-1] 결정 트리 (0) | 2021.04.07 |
| [4-2] 확률적 경사 하강법 (0) | 2021.04.07 |