import numpy as np
import pandas as pd
df = pd.DataFrame({
'지역': ['서울', '서울', '서울', '경기', '경기', '부산', '서울', '서울', '부산', '경기', '경기', '경기'],
'요일': ['월요일', '화요일', '수요일', '월요일', '화요일', '월요일', '목요일', '금요일', '화요일', '수요일', '목요일', '금요일'],
'강수량': [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'강수확률': [80, 70, 90, 10, 20, 30, 50, 90, 20, 80, 50, 10]
})
df
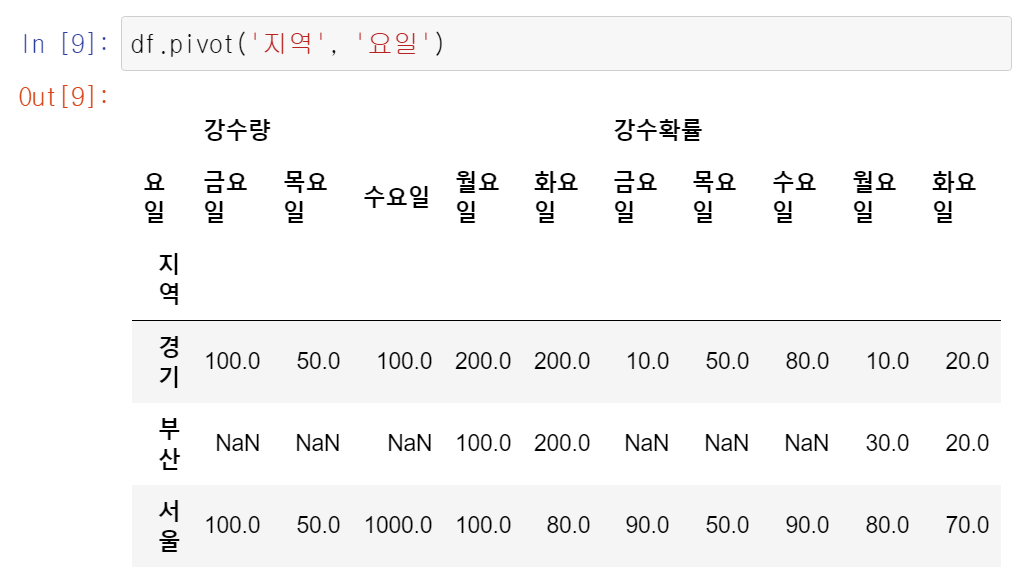
pivot
- dataframe의 형태를 변경
- 인덱스, 컬럼, 데이터로 사용할 컬럼을 명시
- index가 중복된 값을 가지면 오류발생

pivot_table
- 기능적으로 pivot과 동일
- pivot과의 차이점
- 중복되는 모호한 값이 있을 경우, aggregation 함수 사용하여 값을 채움
df = pd.DataFrame({
'지역': ['서울', '서울', '서울', '경기', '경기', '부산', '서울', '서울', '부산', '경기', '경기', '경기'],
'요일': ['월요일', '월요일', '수요일', '월요일', '화요일', '월요일', '목요일', '금요일', '화요일', '수요일', '목요일', '금요일'],
'강수량': [100, 80, 1000, 200, 200, 100, 50, 100, 200, 100, 50, 100],
'강수확률': [80, 70, 90, 10, 20, 30, 50, 90, 20, 80, 50, 10]
})
df
# 두번째 서울의 요일을 화요일에서 월요일로 바꿈

'python > pandas' 카테고리의 다른 글
| concat 함수를 활용하여 dataframe 병합시키기 (0) | 2021.03.30 |
|---|---|
| stack, unstack 함수 이해하기 (0) | 2021.03.30 |
| transform 함수 (0) | 2021.03.30 |
| DataFrame group by 이해 (groupby,gorups,grouping) (0) | 2021.03.30 |
| 범주형 데이터 전처리 하기(one-hot encoding) (.get_dumies) (0) | 2021.03.30 |