- Pyramid Pooling 모듈의 서브 네트워크 구조
Pyramid Pooling 모듈은 PyramidPooling 클래스로 이루어진 하나의 서브 네트워크로 구성되었다. 다음 그림은 PyramidPooling 클래스의 구조이다.
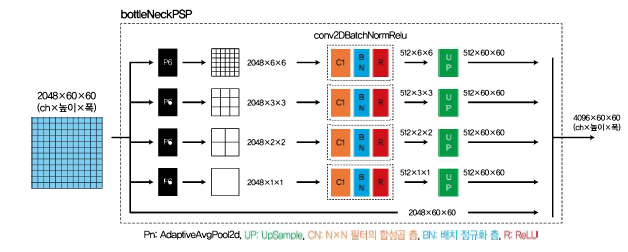
Pyramid Pooling 모듈의 입력은 Feature 모듈에서 출력된 크기 2048x60x60의 텐서이다. 이 입력이 다섯 개로 분기된다. 가장 위의 분기는 Adaptive Average Pooling(출력=6)으로 보내진다. Adaptive Average Pooling층은 출력을 통해 화상(높이 x 폭)을 지정된 크기로 변환되도록 Average Pooling을 한다. 즉 60x60 해상도였던 입력이 특징량 스케일을 6x6 해상도로 변환할 수 있다. Adaptive Average Pooling층의 출력이 1일 경우에는 60x60 크기였던 입력 화상(특징량 화상)이 1x1 의 특징량이다.
다섯 분기 중 네 개는 출력이 각각 6,3,2,1인 Adaptive Average Pooling 층으로 보내진다. 이렇게 출력되는 특징량 맵의 크기가 서로 다른 Average Pooling 층을 사용하면서 원래 입력 화상에 다양한 크기의 특징량 처리(멀티 스케일 처리)를 한다. 네 개의 Average Pooling 층에서 출력되는 특징량 맵의 크기가 점점 커지는 모습이 피라미드와 비슷하여 Pyramid Pooling 이라고 한다.
Average Pooling 층을 통과한 텐서는 conv2dBatchNormRelu 클래스를 지나 Upsample 층에 도달한다. Upsample 층에서는 Average Pooling 층으로 작아진 특징량의 크기를 Pyramid Pooling 모듈의 입력 크기와 같은 60x60 크기로 확대한다. 확대하는 방법은 단순한 화상 확대 처리이다. 확대할 때 bilinear 처리로 보완한다.
다섯 개 분기 중 마지막 한 개는 입력을 출력으로 그대로 보내 네 개의 분기와 최종적으로 결합시킨다.
Pyramid Pooling 모듈의 출력 텐서는 Pyramid Pooling으로 멀티 스케일 정보를 가진다. 해결하고자 한 문제는 '어떠한 픽셀의 물체 라벨을 구하려면 다양한 크기로 해당 픽셀 주변 정보가 필요'한 점이였다. 멀티 스케일 정보를 가진 Pyramid Pooling 모듈의 출력 텐서는 각 픽셀의 클래스를 정할 때 해당 픽셀 주변에 있는 다양한 스케일의 특징량 정보를 사용할 수 있어 높은 정밀도로 시맨틱 분할을 실현할 수 있다.
- PyramidPooling 클래스 구현
class PyramidPooling(nn.Module):
def __init__(self, in_channels, pool_sizes, height, width):
super(PyramidPooling, self).__init__()
# forward에 사용하는 화상 크기
self.height = height
self.width = width
# 각 합성곱 층의 출력 채널 수
out_channels = int(in_channels / len(pool_sizes))
# 각 합성곱 층을 작성
# 다음은 for문으로 구현하는 것이 낫지만, 이해를 돕기 위해 하나하나 나열하고 있습니다
# pool_sizes: [6, 3, 2, 1]
self.avpool_1 = nn.AdaptiveAvgPool2d(output_size=pool_sizes[0])
self.cbr_1 = conv2DBatchNormRelu(
in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, bias=False)
self.avpool_2 = nn.AdaptiveAvgPool2d(output_size=pool_sizes[1])
self.cbr_2 = conv2DBatchNormRelu(
in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, bias=False)
self.avpool_3 = nn.AdaptiveAvgPool2d(output_size=pool_sizes[2])
self.cbr_3 = conv2DBatchNormRelu(
in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, bias=False)
self.avpool_4 = nn.AdaptiveAvgPool2d(output_size=pool_sizes[3])
self.cbr_4 = conv2DBatchNormRelu(
in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, bias=False)
def forward(self, x):
out1 = self.cbr_1(self.avpool_1(x))
out1 = F.interpolate(out1, size=(
self.height, self.width), mode="bilinear", align_corners=True)
out2 = self.cbr_2(self.avpool_2(x))
out2 = F.interpolate(out2, size=(
self.height, self.width), mode="bilinear", align_corners=True)
out3 = self.cbr_3(self.avpool_3(x))
out3 = F.interpolate(out3, size=(
self.height, self.width), mode="bilinear", align_corners=True)
out4 = self.cbr_4(self.avpool_4(x))
out4 = F.interpolate(out4, size=(
self.height, self.width), mode="bilinear", align_corners=True)
# 최종적으로 결합시킬, dim=1으로 채널 수의 차원으로 결합
output = torch.cat([x, out1, out2, out3, out4], dim=1)
return output'Semantic Segmentation' 카테고리의 다른 글
| 7. 파인튜닝을 활용한 학습 및 검증 실시 (0) | 2021.11.21 |
|---|---|
| 6. Decoder, AuxLoss 모듈 (0) | 2021.11.21 |
| 4. Feature 모듈 설명 및 구현(ResNet) (0) | 2021.11.20 |
| 3. PSPNet 네트워크 구성 및 구현 (0) | 2021.11.20 |
| 2. 데이터셋과 데이터 로더 구현 (0) | 2021.11.20 |