- Optimizer 클래스
class Optimizer:
def __init__(self):
self.target = None
self.hooks=[]
def setup(self,target):
self.target=target
return self
def update(self):
params=[p for p in self.target.params() if p.grad is not None]
for f in self.hooks:
f(params)
for param in params:
self.update_one(param)
def update_one(self,param):
raise NotImplementedError()
def add_hook(self,f):
self.hooks.append(f)Optimizer 클래스의 초기화 메서드에서는 target과 hooks라는 두 개의 인스턴스 변수를 초기화한다. 그리고 setup 메서드는 매개변수를 갖는 클래스(Model 또는 Layer)를 인스턴스 변수인 target으로 설정한다.
- SGD 클래스 구현
class SGD(Optimizer):
def __init__(self,lr=0.01):
super().__init__()
self.lr=lr
def update_one(self,param):
param.data -= self.lr * param.grad.data
- SGD 클래스를 사용한 문제 해결
import numpy as np
from dezero import Variable
from dezero import optimizers
import dezero.functions as F
from dezero.models import MLP
np.random.seed(0)
x=np.random.rand(100,1)
y=np.sin(2*np.pi*x) + np.random.rand(100,1)
lr=0.2
max_iter=10000
hidden_size=10
model=MLP((hidden_size,1))
optimizer=optimizers.SGD(lr)
optimizer.setup(model)
for i in range(max_iter):
y_pred=model(x)
loss=F.mean_squared_error(y,y_pred)
model.cleargrads()
loss.backward()
optimizer.update()
if i % 1000 ==0:
print(loss)
- SGD 이외의 최적화 기법
기울기를 이용한 최적화 기법은 다양하다. 대표적인 기법으로는 Momenutm, AdaGrad, AdaDelta, Adam등을 들 수 있다.
Momentum 기법을 수식으로 표현하면 다음과 같다.
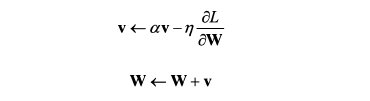
class MomentumSGD(Optimizer):
def __init__(self,lr=0.01,momentum=0.9):
super().__init__()
self.lr=lr
self.momentum=momentum
self.vs={}
def update_one(self,param):
v_key=id(param)
if v_key not in self.vs:
self.vs[v_key] = np.zeros_like(param.data)
v=self.vs[v_key]
v *= self.momentum
v -= self.lr * param.grad.data
param.data += v
'Deep learning > 모델 구현' 카테고리의 다른 글
| 파인튜닝 구현 (0) | 2021.11.20 |
|---|---|
| 36. Model 클래스 (0) | 2021.10.23 |
| 35. 매개변수를 모아두는 계층 (0) | 2021.10.17 |
| 34. 신경망 (0) | 2021.10.17 |
| 33. 형상 변환 함수, 합계 함수 (0) | 2021.10.16 |