이번 포스팅에서는 AlexNet 논문을 리뷰하고 구현해 보겠다.
Abstract
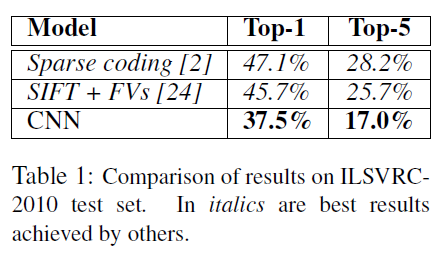
이 논문의 저자들은 1.2million images를 LSVRC-2010 contest 에서 1000개의 클래스로 분류했다. top-1 과 top-5 오류율은 각각 37.5%, 17.0% 였고, 이는 이전에 비해 상당히 발전된 성능이였다. 이 network는 60million 파라미터와 650,000개의 뉴런으로 구성되어있고, 5개의 합성곱층, 그리고 그 뒤에 바로 이어지는 maxpooling층으로 구성되어있다. 그다음 3개의 완전 연결층으로 연결되어있고, 활성화 함수는 softmax 함수를 사용했다. 더 빨리 학습하기 위해서 포화되지 않은 뉴런을 사용했다. 과대적합을 막기 위해서 완전연결층에 dropout 기법을 사용했다.
Introduction
이 논문이 쓰여진 시점에서 논문의 저자들은 object recognition 에서는 머신러닝 방법을 사용하는 것은 필수적이게 되었다고 한다. 그들의 성능을 개선시키기 위해선 우리는 더 큰 datasets을, 더 powerful한 models를, 과대적합을 막기위해 더 좋은 기술을 사용해야 했다.
간단한 recognition task들은 잘 작동했지만, 실제로 존재하는 개체는 상당한 가변성을 보이므로 인식하기 위해서는 훨씬 더 큰 training set를 사용해야 한다.
수백만 images에 있는 수천의 objects를 학습하기 위해선 우리는 큰 용량의 학습 모델이 필요했고 CNN은 이러한 모델을 구현할수 있다. CNN의 용량은 그들의 깊이와 넓이를 다양화시킬수 있고, 그들은 자연의 image에 대해 대부분 정확한 추측을 할 수 있다.
이 논문의 구체적인 기여는 다음과 같다. 논문의 저자들은 ILSVRC-2010과 ILSVRC-2012에서 사용된 ImageNet의 서브셋에 대해 이때까지 가장 큰 합성곱 신경망을 훈련했고, 이 데이터셋에 알려진 결과중 단연코 최고의 성능을 냈다. 이들의 network는 5개의 합성곱층과 3개의 완전연결층으로 구성되어있는데 이 깊이는 매우 중요하다. 이들은 어떤 합성곱층을 없애든 나쁜 성능을 나타냈다고 언급하였다.
The Dataset
1. 22,000개 카테고리로 구성되어 있고 1500만개의 고해상도 이미지가 포함되어있는 data set이다. ILSVRC 대회는 ImageNet dataset의 subset을 이용하는데, 각 카테고리당 1000개의 이미지가 포함되어 있는 1000개 카테고리를 이용한다. 따라서, 대략 120만개의 training 이미지와 50,000개의 validation 이미지, 150,000개의 testing 이미지로 구성되있다.
2. 이미지를 동일한 크기 (256x256)으로 고정시켰다. 나중에 완전연결층의 입력 크기가 고정되어있어야 하기 때문이다. 이미지의 넓이와 높이 중 더 짧은 쪽을 256으로 고정시키고 중앙 부분을 256x256 크기로 crop하였다.
3. 각 이미지의 픽셀에 training set의 평균을 빼서 정규화시켜주었다.
The Architecture

8개의 층으로 구성되어져있는데 5개의 합성곱층과 3개의 완전연결층으로 구성되어있다. 이 구조에는 중요한 4가지 특징이 있다.
1. ReLU Nonlinearity

깊은 합성곱 신경망에서 ReLU 함수를 활성화 함수로 사용하면 tanh 함수를 사용한것 보다 몇배 더 빠른 훈련속도를 낼 수 있다.

2. Training on Multiple GPU
이 논문의 저자들은 memory 부족때문에 두개의 GPU로 병렬처리하여 학습을 진행했다.
3. Local Response Normalization(경쟁적 정규화)
AlexNet은 또 C1과 C3층의 ReLU 단계 후에 바로 LRN이라고 부르는 경쟁적인 정규화 단계를 사용했다. 가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치에 있는 뉴런을 억제한다. 이는 특성 맵을 각기 특별하게 다른 것과 구분되게 하고, 더 넓은 시각에서 특징을 탐색하도록 만들어 결국 일반화 성능을 향상시킨다.

예를 들어 r=2이고 한 뉴런이 강하게 활성화되었다면 자신의 위와 아래의 특성 맵에 위치한 뉴런의 활성화를 억제할 것이다. AlexNet에서 하이퍼파라미터는 r=2, a=0.00002, b=0.75, k=1 로 설정되어있다. 이 단계는tf.nn.local_response_normalization() 연산을 사용하여 구현할 수 있다 ( 이 함수를 케라스 모델에 사용하고 싶다면 Lambda 층으로 감싼다).
4. overlapping pooling
전통적으로는 pooling층이 사용될때 인접한 뉴런을 겹치게 풀링하지 않았다. 그런데 이 논문의 저자들은 인접한 뉴런을 겹치게 pooling하면(예를들어 pooling층의 기본적인 stride=2 인데 stride=1 로 지정하면) 과대적합을 방지하는데 도움을 줄 수 있다는것을 관찰했다.
<Overall Architecture>
두번째, 네번쨰, 다섯번째 합성곱층은 같은 GPU내에서 처리된 이전층과 연결되어 있다. 세번째 합성곱층은 모든 이전층과 연결되어있다. 완전연결층은 이전층의 모든 뉴런과 완전연결 되어 있다.
Response-normalization층이 첫번째, 두번째 합성곱 층 뒤에 따라오고, Max-pooling층은 첫번째, 두번째 normalization층 뒤에, 그리고 다섯번째 합성곱층 뒤에 따라온다.
ReLU 활성화 함수는 모든 합성곱층과, 완전연결층의 활성화함수로 사용된다.
첫번째 합성곱층: 224x224x3 input image를 받고 96개의 11x11x3 size의 커널, stride=4로 구성되어 있다.
두번째 합성곱층: 5x5x3 사이즈의 256개의 커널로 구성되어 있다.
세번째, 네번쨰, 다섯번째 합성곱층: 정규화층이 연결되어있다. 3x3x3 사이즈의 각각 384,384,256 개의 커널로 구성되어 있다.
완전연결층: 각각 4096개의 뉴런으로 구성되어있다.
Reducing Overfitting
1. Data Augmentation
Data Augmentation은 데이터를 다양하게 만들어 CNN 모델을 학습시키기 위해 만들어진 개념이다. 이러한 기법은 적은 노력으로 다양한 데이터를 형성하게하여 overfitting을 피하게 만들어 준다. 또한 data augmentation의 연산량은 매우 적고 CPU에서 이루어지기 때문에 계산적으로 부담이 없다고 논문에 나와있다.
이 논문에서 2가지 data augmentation 를 적용했다.
- generating image translation and horizontal reflections
이미지를 생성시키고 수평 반전을 해주었다고 한다.
256x256 이미지에서 224x224 크기로 crop을 한다. crop 위치는 중앙, 좌측 상단, 좌측 하단, 우측 상단, 우측 하단 이렇게 5개의 위치에서 crop을 한다. crop으로 생성된 5개의 이미지를 horizontal reflection을 한다. 따라서 하나의 이미지에서 10개의 이미지가 생성된다.
- altering the intensities of the RGB channels in training images
image의 RGB pixel 값에 변화를 주었다. ImageNet의 training set에 RGB pixel 값에 대한 PCA를 적용했다. PCA를 수행하여 RGB 각 생상에 대한 eigenvalue를 찾는다. eigenvalue와 평균 0, 분산 0.1인 가우시안 분포에서 추출한 랜덤 변수를 곱해서 RGB 값에 더해준다.
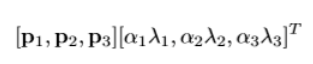
이를 통해 조명의 영향과 색의 intensity 변화에 대한 불변성을 지니게 되었다. 이 기법으로 top-1 error를 1% 낮추었다고 한다.
2. Dropout
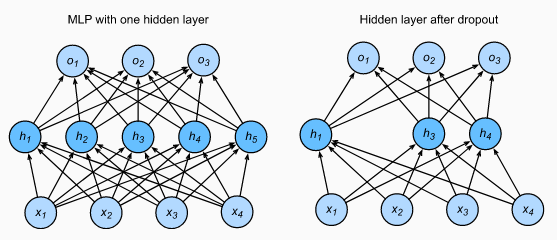
dropout이라고 불리는 기술은 50%의 확률로 각각의 hidden neuron의 output을 0으로 만들어주는 기술이다. dorp out된 뉴런들은 forward pass 와 backpropaagation에 영향을 주지 않는다. 그러므로 input이 입력될때마다 새로운 구조의 뉴런이 생성된다. 그러나 이들은 가중치는 공유한다. 이 기술은 뉴런이 특정한 다른 뉴런의 존재에 의존할수 없기 때문에 뉴런의 complex co-adaptations 을 감소시킨다. 그러므로 이 방법을 통해 강력한 특징들을 학습할수 있게 된다.
논문의 저자들은 dropout을 첫번째, 두번째 완전연결층에 사용했다. dropout층이 없을때는 상당한 overfitting이 나타났다. Dropout은 수렴에 필요한 반복횟수를 2배로 늘린다.
Details of learning
논문 저자들은 stochastic gradient descent, 128 bath size를 사용해서 훈련했고, momentum은 0.9 그리고 weight decay를 0.0005로 설정했다. 이들은 이러 적은 양의 weight decay는 모델 학습에 중요하다는 것을 발견했다. weight decay는 단순히 regularizer 역할을 할 뿐만 아니라, 모델의 훈련 에러를 줄어주었다.
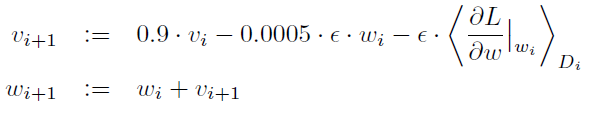


논문의 저자들은 각각의 층의 가중치를 표준편차가 0.01이고, 평균이 0인 가우시안분포로 초기세팅했다. 또한 두번째, 네번째, 다섯번째 합성곱층과 완전연결층의 bias를 1로 세팅했다. 이 초기 설정은 ReLU활성화 함수의 input을 양수로 줄수 있어서 초기학습 속도를 가속시킬수 있다. 남은 층들의 bias는 0으로 세팅했다. 마지막으로 학습률은 0.01으로 지정했다.
Results and discussion
크고 깊은 합성곱 신경망은 순전히 supervised learning을 통해 어려운 dataset에 대해 상당히 훌룡한 결과를 낼 수 있다는 능력이 있다는것을 보여주었다. 만약 합성곱층의 한층만이라도 손상된다면 약 2%의 성능 저하가 나타난것을 알 수 있었다. 그러므로 깊이는 정말 중요한 요소인것을 알 수 있다.
이들은 실험을 단순화하기 위해, 특히 라벨링된 데이터의 양의 상응하는 증가를 얻지 않고 네트워크의 크기를 크게 늘릴 수 있는 충분한 연산 능력을 얻는 경우, 도움이 될 것으로 예상함에도 불구하고, 이들은 감독되지 않은 사전 훈련을 사용하지 않았다.
구현
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
CLASS_NAMES= ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
x_train,x_val,y_train,y_val=train_test_split(x_train,y_train,test_size=0.1)
print(x_train.shape,x_val.shape)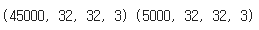
train_ds = tf.data.Dataset.from_tensor_slices((x_train,y_train))
test_ds = tf.data.Dataset.from_tensor_slices((x_test,y_test))
validation_ds = tf.data.Dataset.from_tensor_slices((x_val,y_val))
def process_images(image, label):
# Resize images from 32x32 to 277x277
image = tf.image.resize(image, (227,227))
return image, labeltrain_ds = train_ds.batch(batch_size=128, drop_remainder=True)
test_ds = test_ds.batch(batch_size=128, drop_remainder=True)
val_ds = validation_ds.batch(batch_size=128, drop_remainder=True)
train_ds=train_ds.map(process_images)
test_ds=test_ds.map(process_images)
val_ds=val_ds.map(process_images)
from keras.models import Sequential
from keras.layers import Dense,Conv2D,Flatten,MaxPool2D,BatchNormalization,Dropout
class AlexNet(Sequential):
def __init__(self):
super().__init__()
self.add(Conv2D(96,11,strides=4,activation='relu',input_shape=(227,227,3)))
self.add(BatchNormalization())
self.add(MaxPool2D(3,2))
self.add(Conv2D(256,5,strides=1,activation='relu',padding='same'))
self.add(BatchNormalization())
self.add(MaxPool2D(3,2))
self.add(Conv2D(384,3,strides=1,activation='relu',padding='same'))
self.add(BatchNormalization())
self.add(Conv2D(384,3,strides=1,activation='relu',padding='same'))
self.add(BatchNormalization())
self.add(Conv2D(256,3,strides=1,activation='relu',padding='same'))
self.add(BatchNormalization())
self.add(MaxPool2D(3,2))
self.add(Flatten())
self.add(Dense(4096,activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(4096,activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(10,activation='softmax'))
self.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics='accuracy')
model=AlexNet()
model.summary()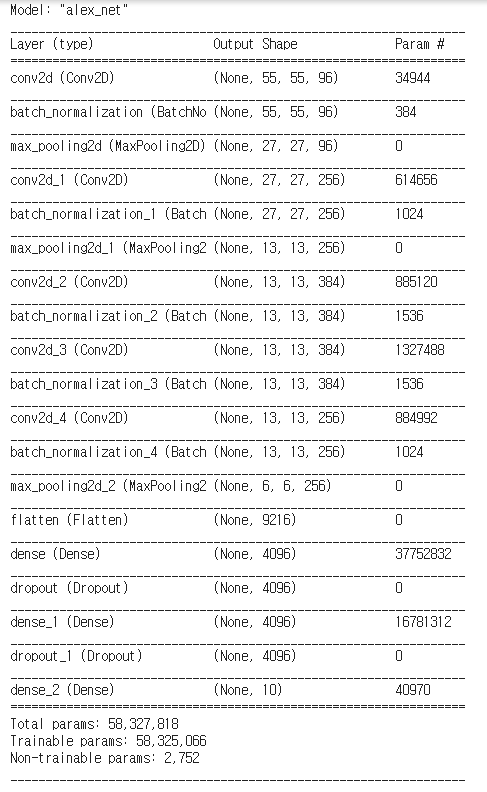
'논문 리뷰, 구현' 카테고리의 다른 글
| 6. ResNet 논문 리뷰, 구현 (0) | 2022.07.03 |
|---|---|
| 5.Network in Network 논문 리뷰 (0) | 2022.07.03 |
| 4.GoogleNet 논문 리뷰, 구현 (0) | 2022.06.29 |
| 3.VGG 논문 리뷰,구현 (0) | 2022.06.29 |
| 1. LeNet-5 논문 리뷰, 구현(tensorflow) (0) | 2022.06.27 |