

단계 1에서 판별자를 훈련하는 동안 생성자의 파라미터는 변경하지 않는다. 비슷하게 단계 2에서 생성자를 훈련하는 동안 판별자의 파라미터를 그대로 유지한다. 훈련하는 네트워크의 가중치와 절편만 업데이트 하는 이유는 이 네트워크가 제어할 수 있는 파라미터만 바꾸기 위해서이다. 이렇게 하면 각 네트워크는 다른 네트워크의 업데이트에 간섭받지 않고 자신에게 관련된 신호만 업데이트에 적용할 수 있다.
진짜 손글씨 숫자처럼 보이는 이미지를 생성하는 GAN을 만들겠다. 파이썬 신경망 라이브러리인 텐서플로의 케라스 API를 사용한다. 만들고자 하는 GAN의 구조는 다음 그림과 같다.
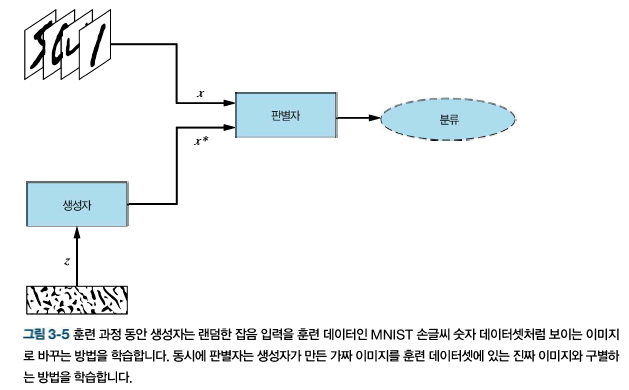
먼저 모델 실행에 필요한 모든 패키지와 라이브러리를 임포트한다.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Dense,Flatten,Reshape
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
둘째, 모델의 입력과 데이터셋의 차원을 지정한다. MNIST는 하나의 채널을 가진 28x28픽셀의 이미지이다. 변수 z_dim는 잡음 벡터 z의 크기를 결정한다.
img_rows=28
img_cols=28
channels=1
img_shape=(img_rows,img_cols,channels) # 입력 이미지 차원
z_dim=100 # 생성자의 입력으로 사용될 잡음 벡터의 크기
<생성자 구현>
간단하게 만들기 위해서 생성자 네트워크는 하나의 은닉층을 가진다. z 벡터를 입력받아 28x28x1 크기 이미지를 생성한다. 은닉층은 LeakyReLU 활성화 함수를 사용한다. 음수 입력을 모두 0으로 만드는 일반적인 ReLU 함수와 달리 LeakyReLU는 작은 기울기를 사용한다. 이 함수는 훈련 중에 그레이디언트가 사라지는 것을 막기 때문에 훈련 결과를 향상시키는 경향이 있다.
출력층에는 tanh 활성화 함수를 사용하여 출력 값을 [-1,1] 범위로 조정한다. tanh를 사용하는 이유는 시그모이드 함수보다 조금 더 또렷한 이미지를 만들기 때문이다.
def build_generator(img_shape,z_dim):
model=Sequential()
model.add(Dense(128,input_dim=z_dim)) # 완전 연결층
model.add(LeakyReLU(alpha=0.01)) # LeakyReLU 활성화 함수
model.add(Dense(28 * 28 * 1,activation='tanh')) # tanh 활성화 함수를 사용한 출력층
model.add(Reshape(img_shape)) # 생성자 출력을 이미지 차원으로 변경
return model
<판별자 구현>
판별자는 28x28x1 크기의 이미지를 받아 가짜와 비교해 얼마나 진짜인지를 나타내는 확률을 출력한다. 판별자는 2개의 층으로 구성된 네트워크이다. 은닉층은 LeakyReLU 활성화 함수와 128개의 은닉 유닛을 가진다.
생성자와 달리 다음 코드에서 판별자의 출력층에 시그모이드 활성화 함수를 적용했다. 이는 출력 값을 0과 1사이로 만들기 때문에 판별자가 입력을 진짜로 생각하는 확률로 해석할 수 있다.
def build_discriminator(img_shape):
model=Sequential()
model.add(Flatten(input_shape=img_shape)) # 입력 이미지를 일렬로 펼치기
model.add(Dense(128)) #완전 연결층
model.add(LeakyReLU(alpha=0.01)) # LeakyReLU 활성화 함수
model.add(Dense(1,activation='sigmoid')) # 시그모이드 활성화 함수를 사용한 출력층
return model
<모델 생성>
앞서 구현한 생성자와 판별자 모델을 만들고 컴파일한다. 생성자를 훈련하기 위해 연결된 모델에서는 판별자의 파라미터를 동결하기 위해 discriminator.trainable을 False로 지정한다. 판별자를 훈련하지 않도록 설정한 이 연결된 모델은 생성자만 훈련하기 위해 사용된다. 판별자는 독립적으로 컴파일된 모델로 훈련한다.
이진 교차 엔트로피를 훈련하는 동안 최소화할 손실 함수로 사용한다. 이진 교차 엔트로피는 두 개의 클래스만 있는 예측에서 계산된 확률과 진짜 확률 사이의 차이를 측정한다. 교차 엔트로피 손실이 클수록 예측이 정답 레이블과 차이가 크다.
각 네트워크를 최적화하기 위해 Adam 최적화 알고리즘을 사용한다. Adam이 대부분 GAN 구현의 기본 옵티마이저이다.
def build_gan(generator,discriminator):
model=Sequential()
model.add(generator)
model.add(discriminator)
return model
discriminator=build_discriminator(img_shape) # 판별자 모델 만들고 컴파일하기
discriminator.compile(loss='binary_crossentropy',optimizer=Adam(),metrics=['accuracy'])
generator=build_generator(img_shape,z_dim) # 생성자 모델 만들기
discriminator.trainable=False # 생성자 훈련할 때 판별자 파라미터 동결하기
gan=build_gan(generator,discriminator) # 생성자를 훈련하기 위해 동결한 판별자로 GAN 모델 만들고 컴파일하기
gan.compile(loss='binary_crossentropy',optimizer=Adam())
<훈련>
다음 코드는 GAN 훈련 알고리즘을 구현한 것이다. 랜덤한 MNIST 이미지의 미니배치를 진짜 샘플로 받고 랜덤한 잡음 벡터 z로부터 가짜 이미지의 미니배치를 생성한다. 그다음 이를 사용해 생성자의 파라미터를 고정한 채로 판별자 네트워크를 훈련한다. 그다음 가짜 이미지의 미니배치를 생성하고 이를 사용해 판별자의 파라미터를 고정한 채로 생성자 네트워크를 훈련한다. 그리고 이 과정을 반복한다.

losses=[]
accuracies=[]
iteration_checkpoints=[]
def train(iterations,batch_size,sample_interval):
(X_train,_),(_,_) = mnist.load_data()
X_train=X_train/127.5 -1.0 #[0,255] 흑백 픽셀 값을 [-1,1] 사이로 스케일 조정
real=np.ones((batch_size,1)) # 진짜 이미지 레이블: 모두 1
fake=np.zeros((batch_size,1)) # 가짜 이미지 레이블: 모두 0
for iteration in range(iterations):
idx=np.random.randint(0,X_train.shape[0],batch_size) #진짜 이미지에서 랜덤 배치 가져오기
imgs=X_train[idx]
z=np.random.normal(0,1,(batch_size,100)) # 가짜 이미지 배치 생성
gen_imgs=generator.predict(z)
d_loss_real= discriminator.train_on_batch(imgs,real) # 판별자 훈련 (1,2)
d_loss_fake=discriminator.train_on_batch(gen_imgs,fake) # (1,2)
d_loss,accuracy= 0.5 * np.add(d_loss_real,d_loss_fake)
z=np.random.normal(0,1,(batch_size,100)) # 가짜 이미지 배치 생성
gen_imgs=generator.predict(z)
g_loss=gan.train_on_batch(z,real) # 생성자 훈련 (1,1)
if (iteration + 1) % sample_interval ==0:
losses.append((d_loss,g_loss)) # 훈련이 끝난 후 그래프를 그리기 위해 손실과 정확도 저장
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
print("%d [D 손실: %f, 정확도: %.2f%%] [G 손실: %f]" %
(iteration + 1, d_loss,100.0 * accuracy,g_loss))
sample_images(generator) # 생성된 이미지 샘플 출력
<샘플 이미지 출력>
생성자 훈련 코드에서 sample_images() 함수를 호출한다. 이 함수를 모든 sample_interval 반복 동안 호출하여 생성자가 합성한 4x4 이미지 그리드를 출력한다. 모델을 실행하고 나서 이 이미지를 통해 중간 출력과 최종 출력을 점검한다.
def sample_images(generator,image_grid_rows=4,image_grid_columns=4):
z=np.random.normal(0,1,(image_grid_rows * image_grid_columns,z_dim)) # (16,100) 사이즈의 정규분포
gen_imgs=generator.predict(z)
gen_imgs=0.5 * gen_imgs + 0.5 # 이미지 픽셀 값을 [0,1] 범위로 스케일 조정
fig,axs=plt.subplots(image_grid_rows,
image_grid_columns,
figsize=(4,4),
sharey=True,
sharex=True)
cnt=0
for i in range(image_grid_rows):
for j in range(image_grid_columns):
axs[i,j].imshow(gen_imgs[cnt,:,:,0],cmap='gray') #이미지 그리드 출력
axs[i,j].axis('off')
cnt+=1
<모델 실행>
훈련 하이퍼파라미터인 반복 횟수, 배치 크기를 설정하고 모델을 훈련한다. 미니배치는 프로세스 메모리에 들어갈 수 있도록 충분히 작아야한다(일반적으로 사용하는 미니배치 크기는 2의 배수이다.) 반복도 많이 할수록 훈련 과정이 길다. 적절한 반복 횟수를 결정하려면 훈련 손실을 모니터링하고 손실이 평탄해지는 부근에서 반복 횟수를 정한다. 이 지점에서는 훈련을 계속하더라고 크게 향상되지 않는다(GAN은 생성 모델이기 때문에 지도 학습 알고리즘만큼 과대 적합을 중요하게 여긴다).
iterations=20000
batch_size=128
sample_interval=1000
train(iterations,batch_size,sample_interval) # 지정된 횟수 동안 GAN 훈련


GAN이 생성한 이미지가 완벽하지는 않지만 이 중 여러 개는 진짜 숫자처럼 보인다. 생성자와 판별자에 2개의 층이 있는 간단한 신경망 구조를 사용하여 놀라운 성과를 냈다.
<판별자와 생성자의 훈련 손실 그래프>
losses=np.array(losses)
#판별자와 생성자의 훈련 손실 그래프
plt.figure(figsize=(15,5))
plt.plot(iteration_checkpoints,losses.T[0],label='Discriminator loss')
plt.plot(iteration_checkpoints,losses.T[1],label='Generator loss')
plt.xticks(iteration_checkpoints,rotation=90) # x의 표현 범위
plt.title('Training Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.legend()
<판별자의 정확도 그래프>
accuracies=np.array(accuracies)
# 판별자의 정확도 그래프
plt.figure(figsize=(15,5))
plt.plot(iteration_checkpoints,accuracies,label='Discriminator accuracy')
plt.xticks(iteration_checkpoints,rotation=90)
plt.yticks(range(0,100,5))
plt.title('Discriminator Accuracy')
plt.xlabel('Iteration')
plt.ylabel('Accuracy (%)')
plt.legend()
'GAN > 이론' 카테고리의 다른 글
| 6. 훈련 평가 (0) | 2021.06.24 |
|---|---|
| 5. DCGAN - 구현 (0) | 2021.06.23 |
| 4. DCGAN - 배치정규화 (0) | 2021.06.23 |
| 2. 생성자와 판별자 (0) | 2021.06.22 |
| 1. GAN 기초: 적대적 훈련 (0) | 2021.06.22 |