아주 큰 심층 신경망의 훈련 속도는 심각하게 느릴 수 있다. 지금까지 훈련 속도를 높이는 네 가지 방법을 보았다. 연결 가중치에 좋은 초기화 전략 적용하기, 좋은 활성화 함수 사용하기, 배치 정규화 사용하기, 사전 훈련된 네트워크의 일부 재사용하기이다. 훈련 속도를 크게 높일 수 있는 또 다른 방법으로는 표준적인 경사 하강법 옵티마이저 대신 더 빠른 옵티마이저를 사용할 수 있다. 모멘텀 최적화, 네스테로프 가속 경사, AdaGrad, RMSProp, Adam, Nadam 옵티마이저가 있다.
< 모멘텀 최적화 >



< 네스테로프 가속 경사 >


< AdaGrad >




< RMSProp >
AdaGrad는 너무 빨리 느려져서 전역 최적점에 수렴하지 못하는 위험이 있다. RMSProp 알고리즘은 훈련 시작부터의 모든 그레이디언트가 아닌 가장 최근 반복에서 비롯된 그레이디언트만 누적함으로써 이 문제를 해결했다. 이렇게 하기 위해 알고리즘의 첫 번째 단계에서 지수 감소를 사용한다.


아주 간단한 문제를 제외하고는 이 옵티마이저가 언제나 AdaGrad보다 훨씬 더 성능이 좋다.
< Adam과 Nadam 최적화 >


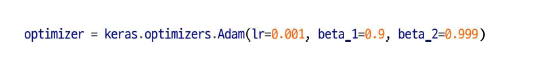

< Adam의 두가지 변종 >


출처 : 핸즈온 머신러닝
'Deep learning > 이론(hands on machine learning)' 카테고리의 다른 글
| 16. 규제를 사용해 과대적합 피하기 (0) | 2021.06.07 |
|---|---|
| 15. 학습률 스케줄링 (0) | 2021.06.07 |
| 13. 사전훈련된 층 재사용 하기 (0) | 2021.06.06 |
| 12. 배치 정규화 (0) | 2021.06.03 |
| 9. 학습률, 배치 크기 (0) | 2021.06.02 |