<시퀀셜 API를 사용하여 이미지 분류기 만들기>
먼저 데이터셋을 적재한다.
fashion_mnist=keras.datasets.fashion_mnist
(X_train_full,y_train_full),(X_test,y_test) = fashion_mnist.load_data()X_train_full.shape #(60000,28,28)
X_train_full.dtype # uint8
이 데이터셋은 이미 훈련 세트와 테스트 세트로 나누어져 있다. 하지만 검증 세트는 없으므로 만들어야 한다. 또한 경사 하강법으로 신경망을 훈련하기 때문에 입력 특성의 스케일을 조정해야 한다. 간편하게 픽셀 강도를 255.0으로 나누어 0~1 사이 범위로 조정하겠다.
X_valid,X_train=X_train_full[:5000]/255.0,X_train_full[5000:]/255.0
y_valid,y_train=y_train_full[:5000],y_train_full[5000:]
X_test=X_test/255.0
패션 MNIST 레이블에 해당하는 아이템을 나타내기 위해 클래스 이름의 리스트를 만들어야한다.
class_names=['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker',
'Bag','Ankle boot']class_names[y_train[0]]

이제 신경망을 만들어 보자. 다음은 두 개의 은닉층으로 이루어진 분류용 다층 퍼셉트론이다.
model=keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300,activation='relu'))
model.add(keras.layers.Dense(100,activation='relu'))
model.add(keras.layers.Dense(10,activation='softmax'))
앞에서와 같이 층을 하나씩 추가하지 않고 Sequential 모델을 만들 때 층의 리스트를 전달할 수 있다.
model=keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(10,activation='softmax')
])
모델의 summary() 메서드는 모델에 있는 모든 층을 출력한다. 각 층의 이름, 출력 크기, 파라미터 개수가 함께 출력된다. 마지막에 훈련되는 파라미터와 훈련되지 않은 파라미터를 포함하여 전체 파라미터 개수를 출력한다.
model.summary()
Dense 층은 보통 많은 파라미터를 가진다. 예를 들어 첫번째 은닉층은 784x300개의 연결 가중치와 300개의 편향을 가진다.

층의 모든 파라미터는 get_weights() 메서드와 set_weights() 메서드를 사용해 접근할 수 있다. Dense 층의 경우 연결 가중치와 편향이 모두 포함되어 있다.
weights,biases=hidden1.get_weights()weights
weights.shape
biases
Dense 층은 연결 가중치를 무작위로 초기화한다. 편향은 0으로 초기화 한다. 다른 초기화 방법을 사용하고 싶다면 층을 만들 때 kernel_initializer와 bias_initializer 매개변수를 설정할 수 있다.

모델을 만들고 나서 compile() 메서드를 호출하여 사용할 손실 함수와 옵티마이저를 지정해야 한다. 부가적으로 훈련과 평가 시에 계산할 지표를 추가로 지정할 수 있다.
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])

마지막으로 분류기이므로 훈련과 평가 시에 정확도를 측정하기 위해 'accuracy' 로 지정한다.
모델을 훈련하려면 간단하게 fit() 메서드를 호출한다.
history=model.fit(X_train,y_train,validation_data=(X_valid,y_valid),epochs=30
)

어떤 클래스는 많이 등장하고 다른 클래스는 조금 등장하여 훈련 세트가 편중되어 있다면 fit() 메서드를 호출할 때 class_weight 매개변수를 지정하는 것이 좋다. 적게 등장하는 클래스는 높은 가중치를 부여하고 많이 등장하는 클래스는 낮은 가중치를 부여한다. 케라스가 손실을 계산할 때 이 가중치를 사용한다. 샘플별로 가중치를 부여하고 싶다면 sample_weight 매개변수를 지정한다 (class_weight 와 sample_weight가 모두 지정되면 케라스는 두 값을 곱하여 사용한다).
fit() 메서드가 반환하는 History 객체에는 훈련 파라미터(history.params), 수행된 에포크 리스트(history.epoch)가 포함된다. 이 객체의 가장 중요한 속성은 에포크가 끝날 때마다 훈련 세트와 검증 세트에 대한 손실과 측정한 지표를 담은 딕셔너리(history.history)이다. 이 딕셔너리를 사용해 판다스 데이터프레임을 만들고 plot() 메서드를 호출하면 다음과 같은 학습 곡선(learning curve)를 볼 수 있다.
import pandas as pd
import matplotlib.pyplot as plt
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1) #수직축의 범위를 [0-1] 사이로 설정한다.
plt.show()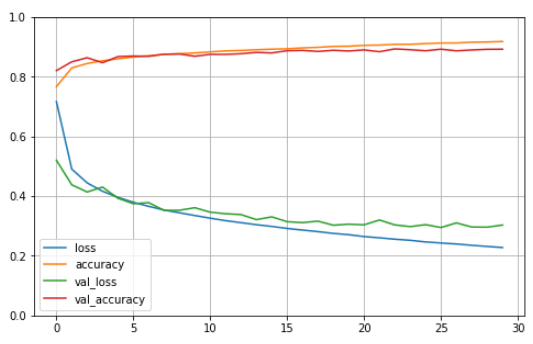
특히 이 경우는 훈련 초기에 모델이 훈련 세트보다 검증 세트에서 더 좋은 성능을 낸 것처럼 보인다. 하지만 사실 그렇지 않다. 검증 손실은 에포크가 끝난 후에 계산되고 훈련 손실은 에포크가 진행되는 동안 계산된다. 따라서 훈련 곡선은 에포크의 절반만큼 왼쪽으로 이동해야 한다. 그렇게 놓고 보면 훈련 초기에 훈련 곡선과 검증 곡선이 거의 완벽하게 일치한다.
케라스에서 fit() 메서드를 다시 호출하면 중지되었던 곳에서 부터 훈련을 이어갈 수 있다.
모델 성능에 만족스럽지 않으면 처음으로 되돌아가서 하이퍼파라미터를 튜닝해야 한다. 맨 처음 확인할 것은 학습률이다. 학습률이 도움이 되지 않으면 다른 옵티마이저를 테스트해봐야 한다(항상 다른 하이퍼파라미터를 바꾼 후에는 학습률을 다시 튜닝해야 한다). 여전히 성능이 높지 않으면 층 개수, 층에 있는 뉴런 개수, 은닉층이 사용하는 활성화 함수와 같은 모델의 하이퍼파라미터를 튜닝해보아야 한다.
모델의 검증 정확도가 만족스럽다면 모델을 상용 환경으로 배포하기 전에 테스트 세트로 모델을 평가하여 일반화 오차를 추정해야 한다. 이때 evaluate() 메서드를 사용한다(이 메서드는 batch_size와 sample_weight 같은 다른 매개변수도 지원한다).
model.evaluate(X_test,y_test)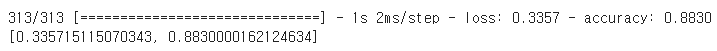
그다음 모델의 predict() 메서드를 사용해 새로운 샘플에 대해 예측을 만들 수 있다. 여기서는 실제로 새로운 샘플이 없기 때문에 테스트 세트의 처음 3개 샘플을 사용하겠다.
X_new=X_test[:3]
y_proba=model.predict(X_new)
y_proba.round(2)
y_pred=model.predict_classes(X_new)
y_pred
np.array(class_names)[y_pred]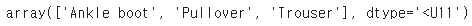
이 분류기를 세 개의 이미지 모두 올바르게 분류했다.
'Deep learning > 이론(hands on machine learning)' 카테고리의 다른 글
| 6. 케라스로 다층 퍼셉트론 구현(3) - 서브클래싱 API, 모델 저장과 복원, 콜백 (0) | 2021.06.02 |
|---|---|
| 5. 케라스로 다층 퍼셉트론 구현(2) - 시퀀셜 API 회귀, 함수형 API (0) | 2021.06.02 |
| 3. 회귀, 분류를 위한 다층 퍼셉트론(MLP-Multi Layer Perceptron) (0) | 2021.05.30 |
| 2. 다층 퍼셉트론과 역전파 (0) | 2021.05.30 |
| 1. 케라스를 사용한 인공 신경망 소개 - 퍼셉트론 (0) | 2021.05.30 |