python/pandas
DataFrame group by 이해 (groupby,gorups,grouping)
jwjwvison
2021. 3. 30. 23:19
import pandas as pd
import numpy as np
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
df = pd.read_csv('./train.csv')
group by
- 아래의 세 단계를 적용하여 데이터를 그룹화(groupping)
- 데이터 분할
- operation 적용
- 데이터 병합
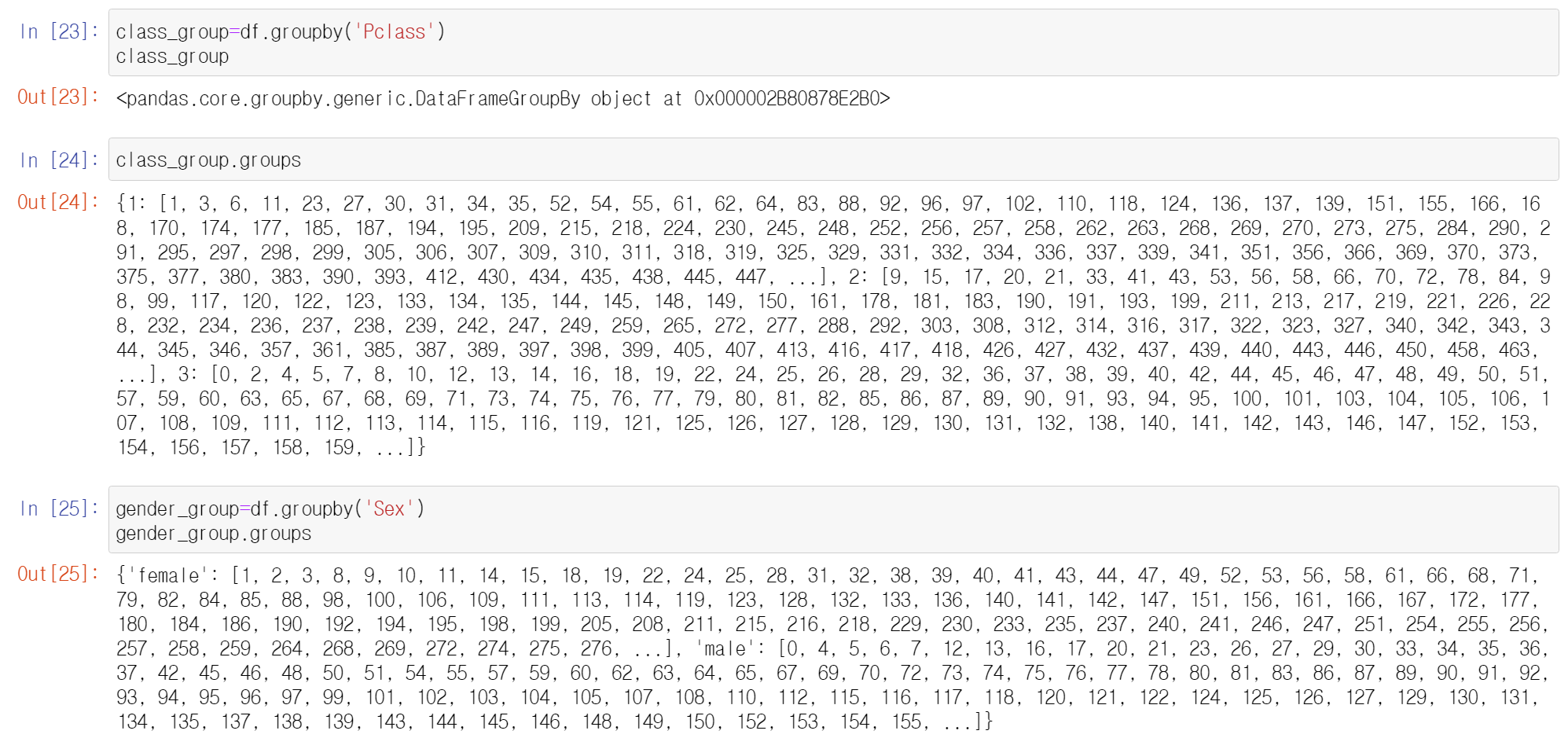
GroupBy group 속성
- 각 그룹과 그룹에 속한 index를 dict 형태로 표현
grouping 함수
- 그룹 데이터에 적용 가능한 통계 함수(NaN은 제외하여 연산)
- count - 데이터 개수
- sum - 데이터의 합
- mean, std, var - 평균, 표준편차, 분산
- min, max - 최소, 최대값

- 성별에 따른 생존율 구해보기

복수 colums로 groupping 하기
- groupby에 column 리스트를 전달
- 통계함수를 적용한 결과는 mulitindex를 갖는 dataframe
- 클래스와 성별에 따른 생존률 구해보기


index를 이용한 group by
- index가 있는 경우, groupby 함수에 level 사용 가능
- level은 index의 depth를 의미하며, 가장 왼쪽부터 0부터 증가
- set_index 함수
- column 데이터를 index 레벨로 변경
- reset_index 함수
- 인덱스 초기화





